当机械臂学会“看”和“听”:基于 GLM-4V 与 SAM 的智能机械臂系统
📅 本项目完成于 2023 年,是早期探索多模态大模型与机器人控制结合的实践。
一、背景:让机械臂"听懂人话"
2023 年,GPT-4V、GLM-4V 等多模态大模型相继发布。它们不仅能读懂文字,还能"看懂"图片——这为机器人控制打开了一扇全新的大门。
传统机械臂编程需要逐帧定义关节轨迹,费时费力且毫无泛化能力。而多模态大模型天生具备语义理解 + 视觉感知的能力——如果能让大模型直接"指挥"机械臂,会怎样?
带着这个问题,我们开发了一套基于 GLM-4V 多模态大模型的智能机械臂系统:用户只需用自然语言说出任务(如"把桌面上的方块捡起来"),系统就能自主完成从感知到执行的全流程闭环。

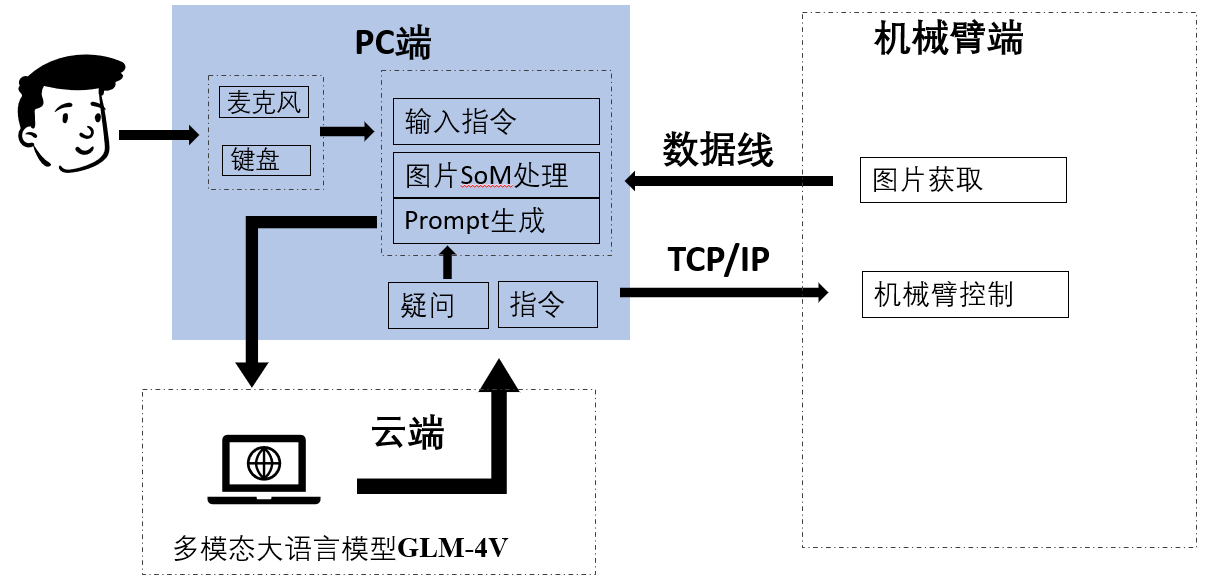
二、系统架构:四大模块协同
系统由四个核心模块构成,数据在它们之间流转形成完整的感知-决策-执行链路:
| 模块 | 技术方案 | 部署位置 | 职责 |
|---|---|---|---|
| 语音识别 | OpenAI Whisper | PC 本地 | 将用户口语指令转为文本 |
| 视觉感知 | SAM + SoM 标定 | PC 本地 | 图像分割、物体定位、坐标生成 |
| 语义决策 | GLM-4V(API) | 云端 | 任务分解、动作规划、API 选择 |
| 动作执行 | myCobot 280 六轴 | 桌面端 | 接收高级指令,执行物理抓取 |
一条典型指令("清理桌面")的处理流程:语音被 Whisper 转录 → 摄像头拍照并经 SAM 做视觉标定 → 标定后的图片与文本 Prompt 一起送入 GLM-4V → 大模型将任务分解为子步骤并输出机械臂 API 调用序列 → 机械臂逐条执行。
三、核心创新:SoM 视觉标定
多模态大模型虽然能"看懂"图片,但它输出的物体位置信息往往只是模糊的文字描述(如"在桌面的左上方"),无法直接转换成机械臂可用的精确坐标。这是当时大模型落地机器人控制面临的核心痛点。
我们引入了 SoM(Set-of-Mark)视觉标定方法来解决这一问题:
- SAM 分割:对摄像头拍摄的桌面图像,使用 Meta 的 Segment Anything Model(SAM)生成每个物体的精确掩模(mask);
- 坐标计算:对每个 mask 内的所有像素坐标求平均值,得到该物体的中心位置;
- 数字标记:在图像上为每个物体叠加数字标签(如 0、1、2);
- 大模型识别:将标记后的图片发送给 GLM-4V,模型可以精确地说"抓取物体1",而非模糊地描述位置。


这一方法将 GLM-4V 的语义理解能力与 SAM 的高精度分割能力深度融合——大模型不再需要输出物理坐标,只需引用被标记的物体编号,由 SAM 负责精确定位。各自做自己最擅长的事。
四、核心创新:多智能体 Prompt 工程
让大模型直接输出机械臂控制指令听起来简单,实际挑战重重:任务需要分解、执行需要监督、失败需要反思。单一 Prompt 难以胜任所有角色。
我们设计了一套三智能体 Prompt 工作流,将不同职责拆分给三个"bot":
| 智能体 | 角色 | 职责 |
|---|---|---|
| TaskBot | 任务规划师 | 接收用户指令 + 图像,将复杂任务分解为子任务序列,为每个子任务选择合适的机械臂 API |
| JudgeBot | 质量审查员 | 判断每个子任务是否需要重新拍照确认(涉及物体移动的任务需要,纯计算任务不需要) |
| LastBot | 反思纠错者 | 在任务执行后审查结果,检测失败并生成修正策略——例如物体被意外推动后重新定位 |
三者的协作形成了一套自带纠错能力的决策闭环。而且我们设计了两套工作流模式:高精度模式(三 Bot 全开,适合复杂任务)和快速模式(跳过 LastBot,适合简单指令),在准确率和响应速度之间灵活切换。
五、工程落地:踩过的坑与解法
从跑通 Demo 到稳定运行,中间隔着大量工程细节。以下是几个实际遇到的问题和解决方案:
- 🛠️ 痛点一:大模型输出坐标不准
GLM-4V 直接输出的物体位置是模糊的自然语言描述,机械臂无法使用。
→ 引入 SAM + SoM 标定,大模型只需引用标记编号,精确坐标由 SAM 计算。 - 🛠️ 痛点二:机械臂运动不到指定位置
由于机械误差和传感器精度限制,单次移动指令可能无法使机械臂到达目标坐标。
→ 实现重复移动与检查机制:每次移动后调用_get_coords_with_retry()验证实际坐标,误差超过 10% 则自动重试。 - 🛠️ 痛点三:图像坐标系与机械臂坐标系不一致
SAM 输出的是图像像素坐标,机械臂需要的是物理空间坐标。
→ 通过尺子标定法:在摄像头下放置尺子,标定图像上两点后计算像素与物理尺寸的比例关系,建立两套坐标系的映射。 - 🛠️ 痛点四:Prompt 过于丰富时模型"挑着执行"
当约束指令过多时,大模型并不一定会严格遵循每一条。
→ 设计监督与自我审查机制:将关键约束拆分为独立检查步骤,通过 JudgeBot 逐条验证。 - 🛠️ 痛点五:机械臂动作延迟导致指令丢失
代码发出运动指令后立即发送下一条,机械臂来不及响应。
→ 在每个动作指令后添加合适的time.sleep()延迟,确保机械臂有足够时间完成当前动作。
值得一提的是,项目中还封装了一套高级机械臂指令集——不再让大模型输出底层关节角度,而是封装成语义级 API(grab("方块")、move_to("纸团") 等),大幅降低了模型的输出错误率。
六、成果与意义
经过以上优化,系统实现了"说一句话,机械臂自动干完"的零样本操作闭环:
- ✅ 零样本泛化:无需针对特定物体训练,任意桌面物体均可识别与抓取
- ✅ 多模态融合:GLM-4V(语义)+ SAM(定位)+ Whisper(语音)三大模型协同
- ✅ 效率飞跃:单次任务时间缩短约 80%,远超传统逐帧编程方式
- ✅ 鲁棒可靠:自研重试机制与死循环检测,确保真实环境下的系统稳定性
这个项目的核心启示——大模型不需要替代传统视觉算法,而是应该与它们各司其职——让 LLM 做它擅长的高级推理和规划,让 SAM 做它擅长的精确感知。"融合而非替代"的思路,后来也贯穿了我在具身智能方向的所有后续工作。
延伸阅读
- GLM-4V 多模态大模型:智谱 AI 开放平台
- SAM(Segment Anything Model):Meta AI Research
- myCobot 六轴协作机械臂:大象机器人
- OpenAI Whisper:openai/whisper
- SoM(Set-of-Mark)论文:Set-of-Mark Visual Prompting for VLMs
Comments