狗品种分类:ResNet152 + Inception v3 + Xception 三模型集成的迁移学习实践
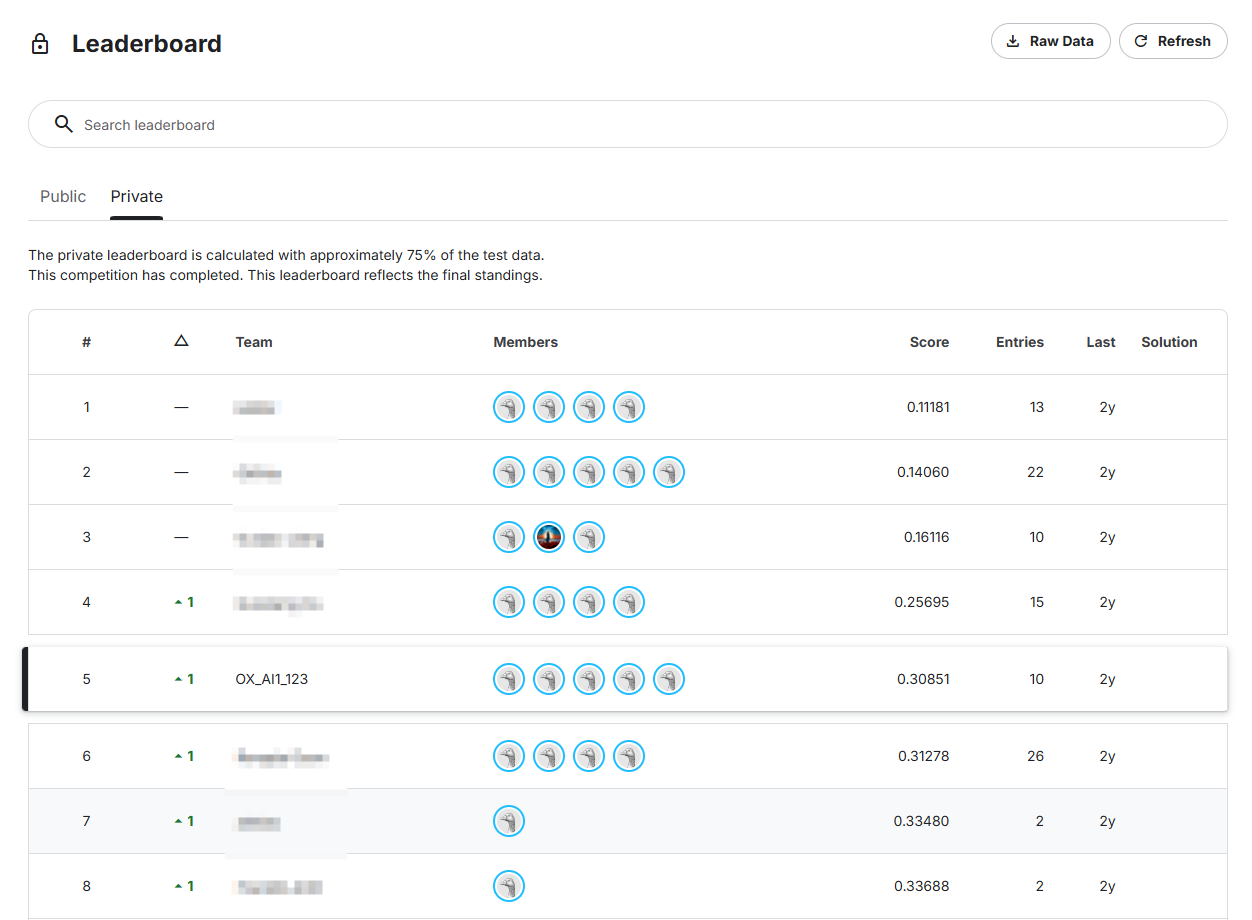
在牛津大学机器学习课程中,我们参加了 Kaggle 狗品种分类竞赛——给定一张狗的照片,模型需从 120 个品种中正确识别其类别。我们采用三模型集成(ResNet152 + Inception v3 + Xception)的迁移学习方案,最终在测试集上达到 91% 分类准确率、Kaggle 得分 0.30508。
其数据分布如下:
一、从单模型到三模型集成的迭代之路
这个项目最值得总结的不是最终方案本身,而是四轮迭代中逐步逼近最优解的过程:
第一轮:单模型起步(失败)
直接用预训练 ResNet50 / EfficientNet-B0,替换最后的全连接层开始训练。结果发现验证集准确率远低于训练集——典型的过拟合。单个模型的 2048 维特征向量不足以覆盖 120 个品种的细粒度差异。
第二轮:冻结参数 + 数据增强(部分改善)
冻结 ResNet50 卷积层权重、仅训练最后的 FC 层,配合 RandomCrop、ColorJitter 和 HorizontalFlip 数据增强。过拟合有所缓解,但对复杂图像的分类仍然不稳定。
第三轮:双模型特征融合(持续进步)
引入 Inception v3 与 ResNet152 并行提取特征,将两个模型的 2048 维特征向量拼接为 4096 维。多尺度特征(Inception)与深层特征(ResNet)互补,准确率明显提升,但训练时间翻倍且部分冗余特征导致新的过拟合。
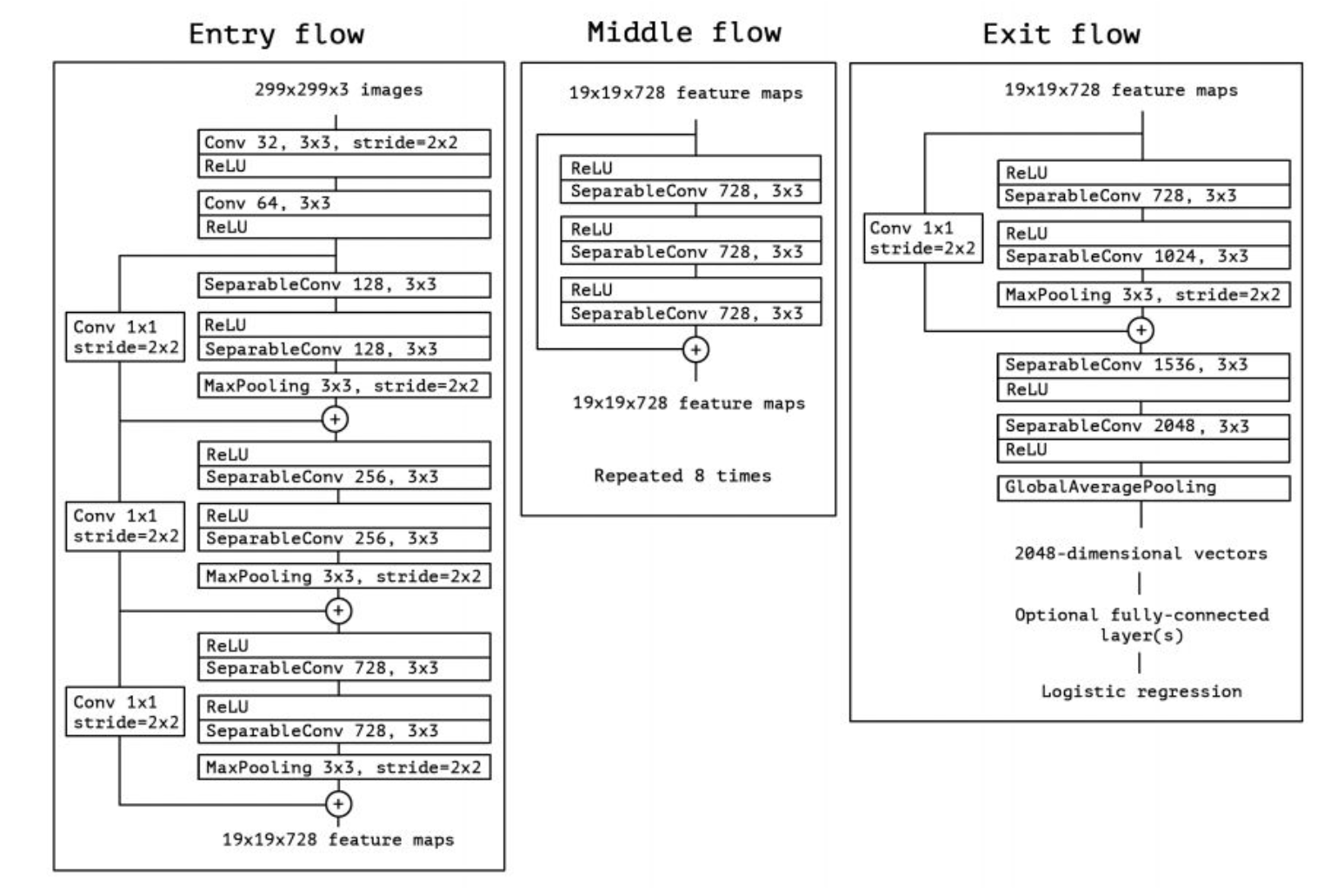
第四轮:三模型集成 + 动态学习率(最佳)
最终方案:ResNet152 + Inception v3 + Xception 三模型并行,各自冻结预训练权重,拼接 6144 维特征向量送入最终全连接层:
class CombinedResNetInception(nn.Module):
def __init__(self, n_class):
# 加载三个预训练模型
self.resnet = models.resnet152(pretrained=True)
self.inception = models.inception_v3(pretrained=True)
self.xception = timm.create_model('xception', pretrained=True)
# 冻结全部卷积层权重
for param in self.resnet.parameters(): param.requires_grad = False
for param in self.inception.parameters(): param.requires_grad = False
for param in self.xception.parameters(): param.requires_grad = False
# 移除分类头,保留特征提取器
self.inception.fc = nn.Identity()
self.xception.fc = nn.Identity()
self.resnet.fc = nn.Identity()
# 拼接 2048×3 = 6144 维 → 120 类
self.fc = nn.Linear(2048 + 2048 + 2048, n_class)
def forward(self, x):
x_resnet = self.resnet(x)
x_inception = self.inception(x)
x_xception = self.xception(x)
x = torch.cat((x_resnet, x_inception, x_xception), dim=1)
return self.fc(x)配合 Adam 优化器(lr=0.0001)+ ReduceLROnPlateau(patience=2, factor=0.5)动态调整学习率,训练在验证集准确率不再提升时自动提前停止。
二、训练策略
- 迁移学习:三个模型均在 ImageNet 上预训练,冻结特征提取层,仅训练最后的 FC 分类头
- 数据增强:RandomResizedCrop(299) + RandomHorizontalFlip + Normalize —— Inception/Xception 固定输入 299×299
- 损失函数:CrossEntropyLoss
- 学习率调度:ReduceLROnPlateau 在验证准确率连续 2 轮不提升时减半学习率
- 早停:验证准确率连续多轮不提升即停止训练
三、结果与收获
最终模型在 120 分类任务上达到:
| 指标 | 数值 |
|---|---|
| 测试集准确率 | 91% |
| 平均损失 | 0.009 |
| Kaggle 得分 | 0.30508 |
从对神经网络几乎零基础,到最终搭建三模型集成 Pipeline 并在 Kaggle 上取得可观的成绩——这个项目最核心的收获是面对失败持续迭代的方法论:每次失败都在告诉我们模型还欠缺什么,每次改进都是向着最佳方案的一次逼近。这种调试思路不仅适用于深度学习,也是工程解决问题的通用逻辑。
Comments