使用DeepSeek-R1为任意大语言模型赋予思考能力:API实现介绍
在大语言模型(LLM)应用中,模型的思考过程对提升回答质量至关重要。DeepSeek-R1的输出能力较弱,幻觉率非常高。常用R1参与工作学习的人经常能看到其思考时分析地头头是道,输出的效果却非常差。不过其作为一个专注于推理能力的模型,可以作为"思考引擎"辅助其他模型生成更高质量的回答,以此来获得远超R1以及其使用的目标模型的能力。本文将详细介绍如何在API调用层面实现这一能力增强方案。
核心思路
实现思路直接而有效:使用两次独立的API调用,第一次调用DeepSeek-R1进行深度思考,第二次调用目标模型生成最终回答,同时将DeepSeek-R1的思考过程作为助手(Assistant)消息上下文传递给目标模型。
技术实现
1. DeepSeek-R1思考阶段
首先,调用DeepSeek-R1模型进行推理思考:
async function getReasoning(prompt) {
const response = await fetch('https://api.deepseek.com/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${DEEPSEEK_API_KEY}`
},
body: JSON.stringify({
model: 'deepseek-r1',
messages: [
{ role: 'system', content: '你是一个专注于深度思考的助手。请对用户的问题进行详细分析,探索不同角度,考虑各种可能性。' },
{ role: 'user', content: prompt }
],
temperature: 0.7,
stream: true
})
});
return response;
}2. 目标模型生成最终回答
关键区别在这里:将DeepSeek-R1的思考结果作为Assistant消息传递给目标模型:
async function getFinalResponse(prompt, reasoning) {
const response = await fetch('https://api.yourllmprovider.com/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${TARGET_API_KEY}`
},
body: JSON.stringify({
model: 'your-target-model',
messages: [
{
role: 'system',
content: '你将收到一个问题和来自另一个模型的思考过程。请基于这些思考提供最终答案。思考过程被<think>和</think>标签包围,用户看不到这部分内容。'
},
{ role: 'user', content: prompt },
{ role: 'assistant', content: `<think>${reasoning}</think>` }
],
temperature: 0.5,
stream: true
})
});
return response;
}3. 流式处理与客户端集成
为支持流式响应,实现服务器端代码以处理和转发响应流:
app.post('/api/chat-with-reasoning', async (req, res) => {
const { prompt } = req.body;
// 设置SSE头
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
try {
// 第一步:获取DeepSeek-R1的思考过程
let reasoningText = '';
const reasoningResponse = await getReasoning(prompt);
const reasoningReader = reasoningResponse.body.getReader();
// 向客户端发送思考开始标记
res.write('data: {"choices": [{"delta": {"content": "<think>"}, "index": 0, "finish_reason": null}]}\n\n');
// 处理思考流
let reasoningDone = false;
while (!reasoningDone) {
const { done, value } = await reasoningReader.read();
if (done) {
reasoningDone = true;
continue;
}
const chunk = new TextDecoder().decode(value);
// 解析DeepSeek-R1流式响应
const lines = chunk.split('\n\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const data = JSON.parse(line.slice(6));
if (data.choices && data.choices[0].delta && data.choices[0].delta.content) {
const content = data.choices[0].delta.content;
reasoningText += content;
res.write(`data: {"choices": [{"delta": {"content": "${content.replace(/\n/g, '\\n').replace(/"/g, '\\"')}"}, "index": 0, "finish_reason": null}]}\n\n`);
}
} catch (e) {
// 处理解析错误
}
}
}
}
// 发送思考结束标记
res.write('data: {"choices": [{"delta": {"content": "</think>"}, "index": 0, "finish_reason": null}]}\n\n');
// 第二步:获取最终回答
const finalResponse = await getFinalResponse(prompt, reasoningText);
const finalReader = finalResponse.body.getReader();
// 向客户端指示思考已结束
res.write('data: {"choices": [{"delta": {"content": "\\n辅助思考已结束,以上辅助思考内容用户不可见,请MODEL开始正式输出:"}, "index": 0, "finish_reason": null}]}\n\n');
// 处理最终回答流
let finalDone = false;
while (!finalDone) {
const { done, value } = await finalReader.read();
if (done) {
finalDone = true;
continue;
}
const chunk = new TextDecoder().decode(value);
// 直接转发最终模型的响应
res.write(chunk);
}
// 结束响应
res.write('data: [DONE]\n\n');
res.end();
} catch (error) {
console.error(error);
res.write(`data: {"error": "${error.message}"}\n\n`);
res.end();
}
});实现优化
- 思考过滤:可以在前端或后端过滤掉思考过程,确保用户只看到最终输出
// 前端过滤思考内容示例
let isInThought = false;
const processContent = (content) => {
const lines = content.split('\n');
let filteredContent = '';
for (const line of lines) {
if (line.includes('<think>')) {
isInThought = true;
continue;
}
if (line.includes('</think>')) {
isInThought = false;
continue;
}
if (!isInThought) {
filteredContent += line + '\n';
}
}
return filteredContent;
};- 消息历史处理:对于多轮对话,需要保持完整的对话历史,同时确保思考内容不会泄露给用户
// 维护两套对话历史
const userVisibleHistory = []; // 用户可见的对话历史
const modelFullHistory = []; // 包含思考内容的完整历史
// 添加新的交互
function addInteraction(userMessage, reasoningContent, finalResponse) {
// 用户可见历史只包含用户消息和最终回答
userVisibleHistory.push(
{ role: 'user', content: userMessage },
{ role: 'assistant', content: finalResponse }
);
// 模型历史包含思考过程
modelFullHistory.push(
{ role: 'user', content: userMessage },
{ role: 'assistant', content: `<think>${reasoningContent}</think>` },
{ role: 'assistant', content: finalResponse }
);
}- 思考提示词工程:针对不同类型的任务,可以设计特定的系统提示来引导DeepSeek-R1的思考方向
测试效果
这边使用硅基流动Deepseek-R1 7b的思考模型和grok2模型进行组合(前者免费,后者官网每月150美金)。只进行一次提问。
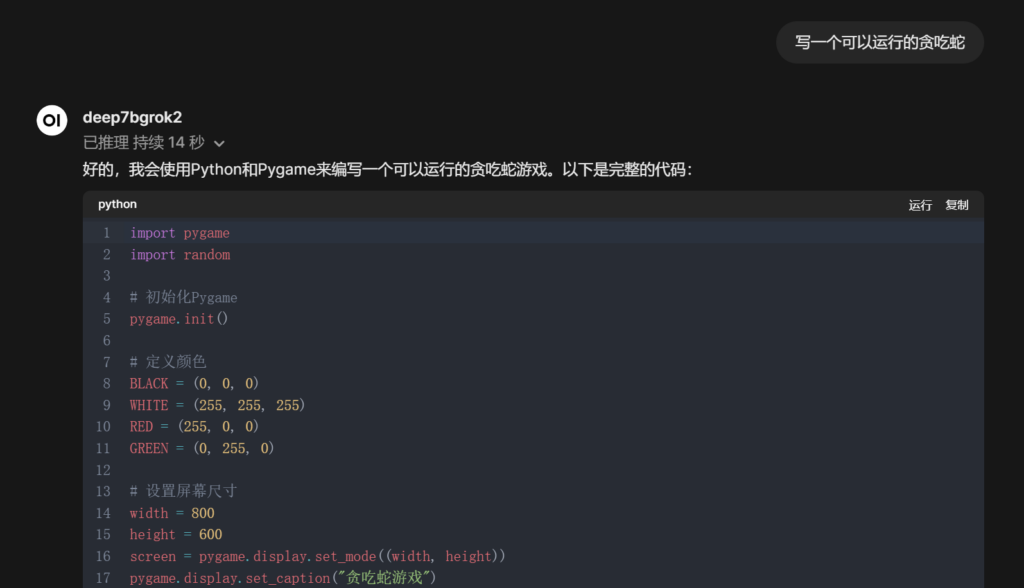
测试结果
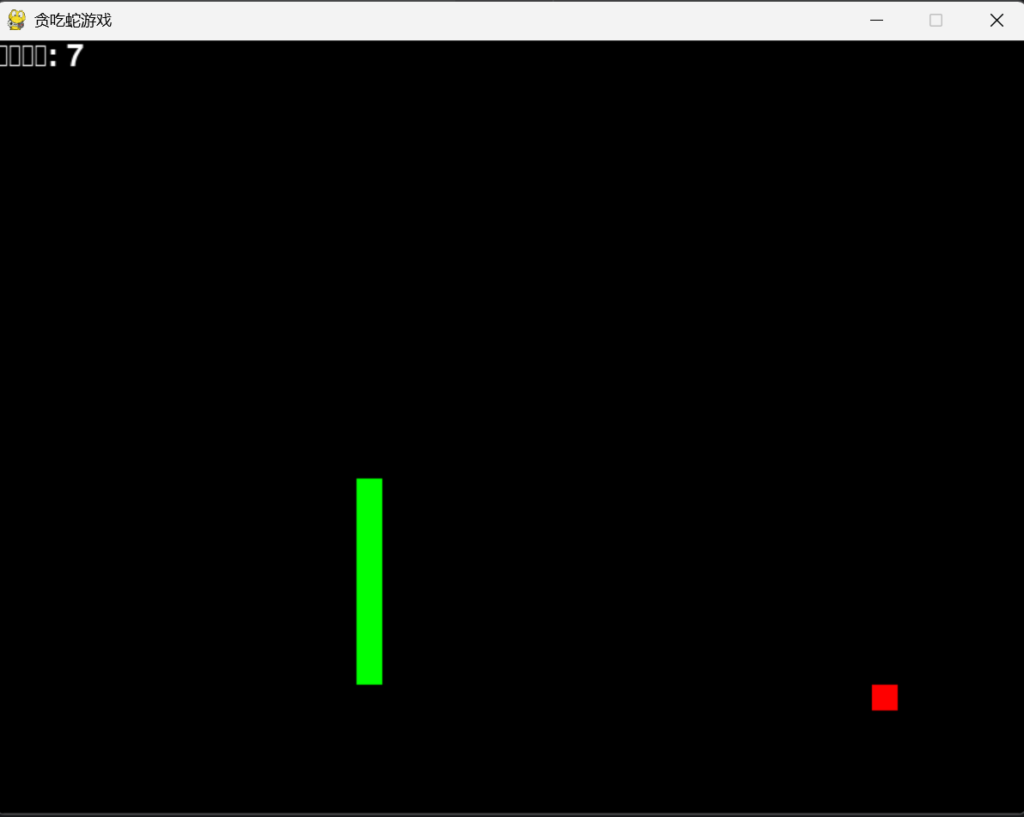
除了文字乱码,暂无其它问题,游戏可以正常运行,正常吃东西、变长、判定失败、不会原地180度转头,并且失败后可以选择继续或者退出。
对照
而单grok2生成的代码却是
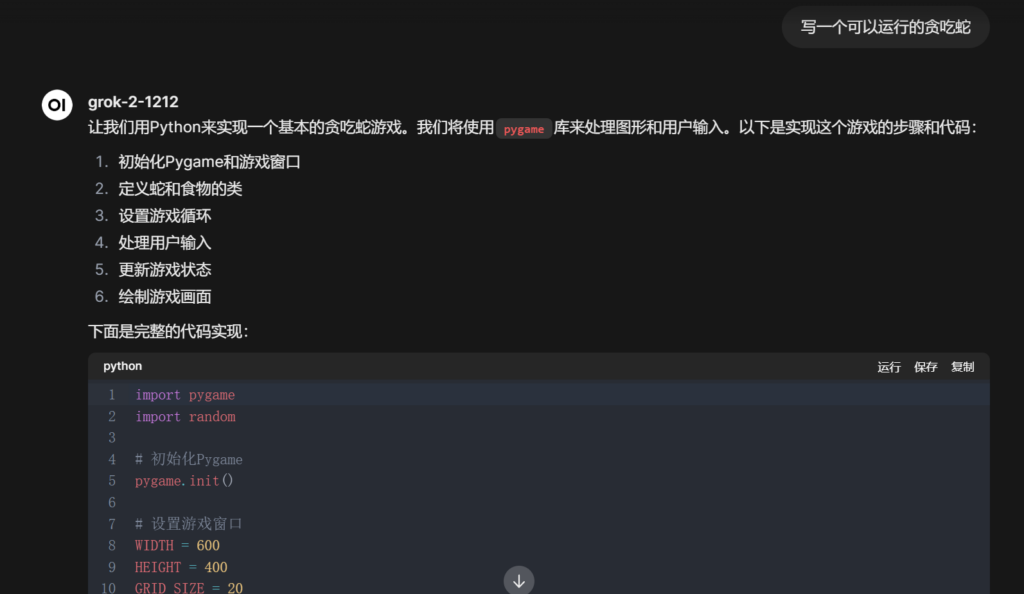
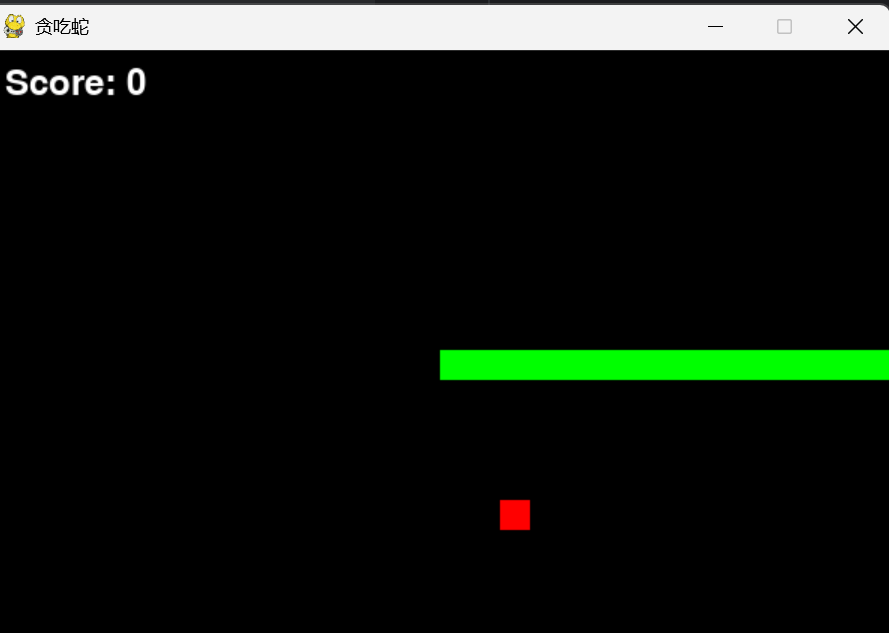
蛇会无限增长,吃到食物或自己都会失败,失败后就直接关闭游戏。
单7b的模型就更不用说了。
想白嫖体验api调用的满血版Deepseek-R1,可以去我之前发的一篇个人汇总里面点击邀请连接,这样我也会有一些额度🥰🥰🥰。
想体验上述deep7bgork2,可以去https://axa.alan-m-12.top/免费使用,在我xai的免费额度用完之前都会一直开着。(不再免费了)
应用场景
这种实现方案可以应用于各种需要深度推理的场景:
- 科学问题解答
- 代码生成与优化
- 数学问题解决
- 复杂决策支持
- 逻辑推理与分析
总结
通过API调用层面的简单集成,我们可以将DeepSeek-R1强大的推理能力与任何大语言模型结合,显著提升最终回答的质量和准确性。这种模式不依赖于特定的模型实现,可以广泛应用于各种LLM应用中。关键在于将思考和回答分离,让专精于推理的模型完成思考部分,让目标模型可以基于这些思考生成更高质量的回答。
Comments