一文搞定大学课程--Python 基础
一、Python 安装
官网下载安装包
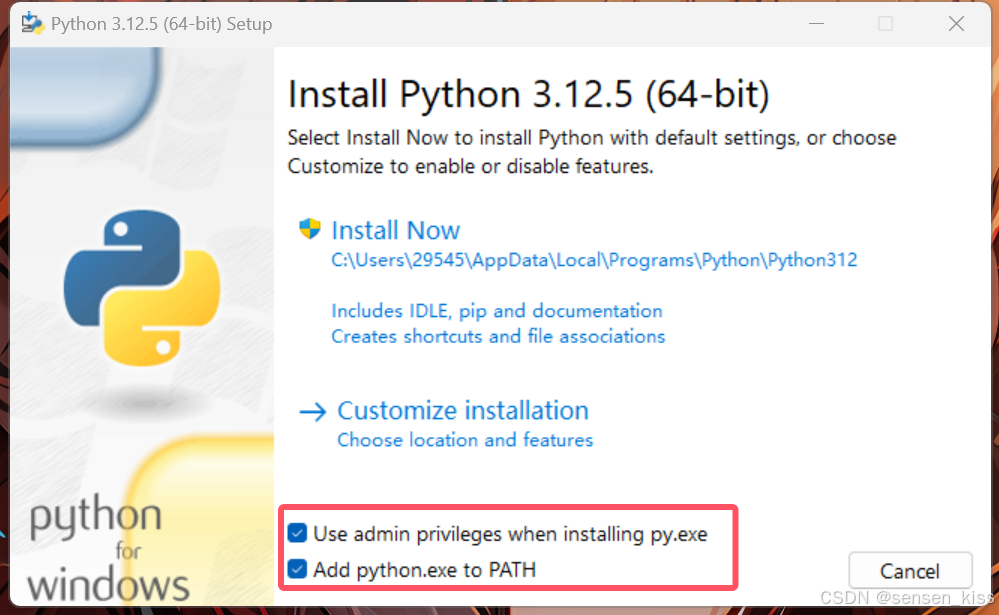
按照步骤安装
注意要勾选下面选项
至此Python 安装完毕,可自行选择vs code或者pycharm作为代码编辑器。
在空文件夹里面创建一个main.py文件,用代码解释器打开并键入以下内容
print("Hello world!")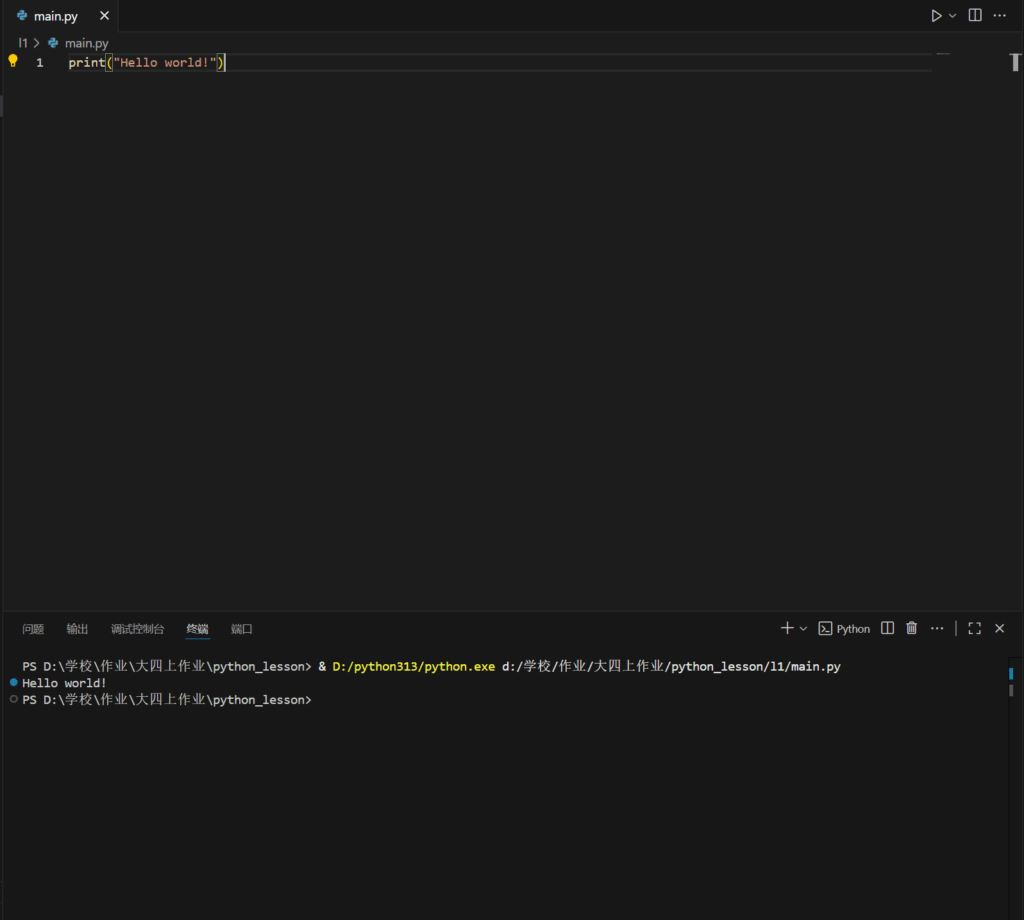
看到正常输出即配置正确。
二、数据格式
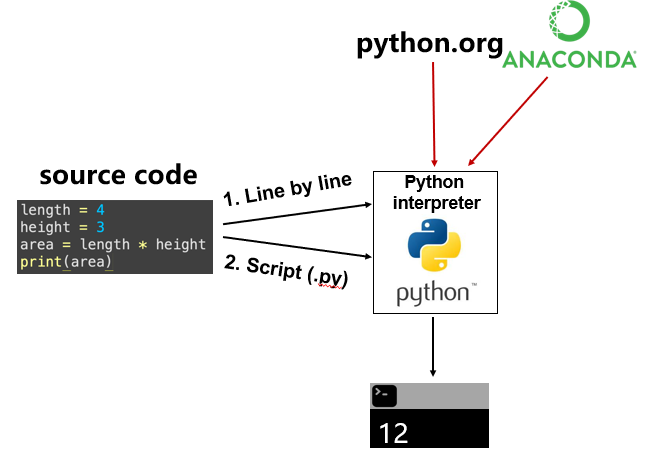
1. 程序是如何运行的?
在我们写代码之前,先花30秒理解一下计算机是如何听懂我们的话的。我们写的代码叫做“源代码”,它需要一个叫做“解释器 (interpreter)”的翻译官,把代码一行一行地翻译成计算机能懂的指令并执行。
2. 万物之始:变量 (Variable)
想象一下,你在整理东西时需要很多箱子,每个箱子上都贴了标签,比如“书”、“玩具”、“衣服”。在编程中,变量就扮演着贴了标签的箱子的角色,用来存放数据。
使用变量非常简单,你只需要给它起个名字,然后用 = 把数据放进去。
# 把 "你好,Python" 这段文字存入名为 message 的变量中
message = "你好,Python"
# 把数字 18 存入名为 age 的变量中
age = 18
# 我们可以随时查看箱子里的东西(打印变量)
print(message)
print(age)变量的特点:
- 无需提前声明:你不需要像某些语言一样提前告诉Python“我要创建一个专门放数字的箱子”,直接用就行。
- 值可以改变:变量里存放的数据随时可以更换。
x = 100
print(x) # 输出 100
x = "现在我变成文字了"
print(x) # 输出 "现在我变成文字了"给变量起名(标识符)的规矩:
- 只能包含字母、数字和下划线 _。
- 严禁使用减号 -(比如 total-sum 是错的,会被当成减法)。
- 严禁包含空格(比如 variable 2 是错的)。
- 不能以数字开头。
- 不能使用 Python 的保留字(比如 def, class, True 等)。
3. Python 的四大基本数据类型
箱子里可以放各种各样的东西,数据也一样,有不同的类型。Python有四种最基础的数据类型。我们可以用 type() 函数来查看一个变量到底是什么类型。
1. 整数 (Integer) 和 浮点数 (Float)
这两种都是数字类型,区别很简单:
- 整数 (Integer):就是不带小数点的数,比如
10,-5,0。 - 浮点数 (Float):就是带小数点的数,比如
3.14,-0.5。
它们可以进行我们熟悉的数学运算。
a = 10
b = 3
print(a + b) # 加法: 13
print(a * b) # 乘法: 30
print(a / b) # 除法: 3.333... (结果总是浮点数)
print(a // b) # 整除: 3 (只保留商的整数部分)
print(a % b) # 取余: 1 (10除以3的余数)
print(a ** b) # 幂运算: 1000 (10的3次方)a. 偷懒的赋值运算 (+=)
程序员都很懒,x = x + 3 这种写法太累,我们通常写成 x += 3。
x = 5y = 3x += y # 等同于 x = x + y,现在 x 变成了 8x *= 2 # 等同于 x = x * 2,现在 x 变成了 16b. 内置函数与求助
Python 自带了很多好用的函数,比如 abs() 用来求绝对值。如果你不知道一个函数怎么用,可以使用 help() 呼叫说明书。
print(abs(-5)) # 输出 5c. 呼叫数学外援 (import math)
基础符号搞不定 π (pi) 或者复杂的三角函数,我们需要导入 math 模块。
import math
print(math.pi) # 输出 3.1415926…计算半径为 10 的圆面积
area = math.pi * (10 ** 2)2. 布尔值 (Boolean)
布尔值最简单,它只有两个值:True (真) 和 False (假)。它就像一个开关,只有开和关两种状态。通常,布尔值是比较和判断的结果。
print(5 > 3) # 5大于3吗? -> True
print(10 == 20) # 10等于20吗? -> False
print(age >= 18) # age变量(值为18)大于等于18吗? -> True我们还会用到 and (与), or (或), not (非) 来组合判断。
3. 字符串 (String)
字符串就是一串文本,需要用单引号 ' ' 或双引号 " " 括起来。
name = "张三"
school = '南方科技大学'字符串的常用操作:
- 拼接 (
+): 把两个字符串连起来。 - 重复 (
*): 把字符串重复多次。
greeting = "你好, "
full_greeting = greeting + name # "你好, 张三"
print(full_greeting)
laugh = "哈" * 3 # "哈哈哈哈"
print(laugh)- 索引 (Indexing): 获取字符串中特定位置的单个字符。注意:索引从 0 开始!
s = "Python"
print(s[0]) # 获取第一个字符 -> 'P'
print(s[2]) # 获取第三个字符 -> 't'
print(s[-1]) # 获取最后一个字符 -> 'n'- 切片 (Slicing): 获取字符串中的一小段。语法是
[开始索引:结束索引],它包含了开始位置,但不包含结束位置。
s = "Python"
print(s[0:2]) # 从索引0取到索引2(不含2) -> "Py"
print(s[2:5]) # 从索引2取到索引5(不含5) -> "tho"
print(s[2:]) # 从索引2取到末尾 -> "thon"
print(s[:4]) # 从开头取到索引4(不含4) -> "Pyth"进阶切片 (Slicing):
切片其实有三个参数:[开始:结束:步长]。
如果不写开始,默认从头切;如果不写结束,默认切到尾。
步长决定了跳着取还是倒着取。
s = "0123456789"
print(s[-3:]) # 从倒数第3个取到末尾 -> "789"
print(s[::3]) # 每隔3个取一次 -> "0369"
print(s[::-1]) # 步长为负,表示字符串反转! -> "9876543210"- 常用方法: 字符串自带很多方便的工具(方法)。
len(s): 获取字符串长度。.lower()/.upper(): 转换成小写/大写。.split('-'): 按指定符号(这里是'-')把字符串分割成一个列表。.replace('旧内容', '新内容'): 替换字符串中的内容。- .
count('x'): 数数某个字符出现了几次。 - .
replace('旧', '新'): 替换内容。 - .
split('_'): 把字符串按指定符号切成列表(文件名处理神器)。
sentence = "I-love-Python"
print(len(sentence)) # 长度是 13
print(sentence.upper()) # "I-LOVE-PYTHON"
print(sentence.split('-')) # ['I', 'love', 'Python']统计 'a' 出现了几次 (注意区分大小写,通常先转大写再统计)
print(dna.upper().count('A'))file_name = "2025_Lab_Exp.tif"print(file_name.split('_')) # ['2025', 'Lab', 'Exp.tif']特殊字符 (Escape Sequences):
如果想在字符串里打印引号或者换行,需要用到“转义字符”,也就是反斜杠 \。
\n: 换行 (New Line)
\' 或 \": 在字符串里打印引号本身,不让它被误认为是字符串的边界。
打印:I say "Hello"
因为外面用了双引号,里面想打印双引号就需要加 \
print("I say \"Hello\"")或者利用三引号 """ """ 来打印多行文本
print("""
第一行
第二行
""")4. 让输出更美观:格式化打印
有时候,我们需要把变量和固定的文字组合在一起输出。最现代、最推荐的方式是使用 f-Strings。只需要在字符串的引号前加一个 f,然后把变量名放在花括号 {} 里。
name = "李四"
age = 20
score = 95.5
# 使用 f-String
print(f"学生姓名: {name}, 年龄: {age}, 成绩: {score}")输出结果:学生姓名: 李四, 年龄: 20, 成绩: 95.5
5. 成为好“码农”的第一步
写代码不仅要让电脑能运行,也要让人能看懂。记住两个好习惯:
- 起有意义的名字:
student_age = 20比a = 20好一万倍。 - 添加注释:对于复杂的代码,用
#在后面加上说明,解释这行代码是干什么的。注释是写给人看的,程序会自动忽略它。
# 这是一个好的例子
# 计算圆的面积
pi = 3.14159
radius = 5
area = pi * (radius ** 2) # 面积公式:π * r²
print(f"半径为 {radius} 的圆,面积为 {area}")三、流程控制
我们写的代码,默认情况下都是从上到下一行一行执行的。但现实世界充满了选择和重复,程序也需要具备这种能力。比如,成绩大于等于60分就算及格,否则就不及格;又比如,我们需要打印100份准考证。
让程序变得“聪明”,能够根据不同情况做出不同反应,或者高效地处理重复任务,这就是我们这章要学习的核心——流程控制 (Flow control)。
它主要包含两个部分:条件判断和循环。
1. 让程序学会“选择”——条件判断 if
条件判断,就是让程序在某个路口做出选择。Python中使用 if 语句来实现。
1. 最简单的 if:满足条件就执行
它的逻辑很简单:如果某个条件成立(为 True),就执行紧跟着的 indented(缩进)代码块。
# 示例:判断考试成绩是否及格
score = 75
if score >= 60:
print("恭喜,你的成绩及格了!")
# 如果 score 是 50,上面这行 print 就不会被执行注意:Python中,代码块的归属关系完全靠缩进来区分。通常我们使用4个空格作为一级缩进。
2. 二选一:if-else
很多时候,我们不仅要处理条件成立的情况,也要处理不成立的情况。这时 if-else 结构就派上用场了。
# 示例:判断一个数是奇数还是偶数
number = 9
if number % 2 == 0:
print(f"{number} 是一个偶数。")
else:
print(f"{number} 是一个奇数。")else 就像是 if 的备用选项,当 if 的条件不满足时,程序就会自动执行 else 下方的代码。
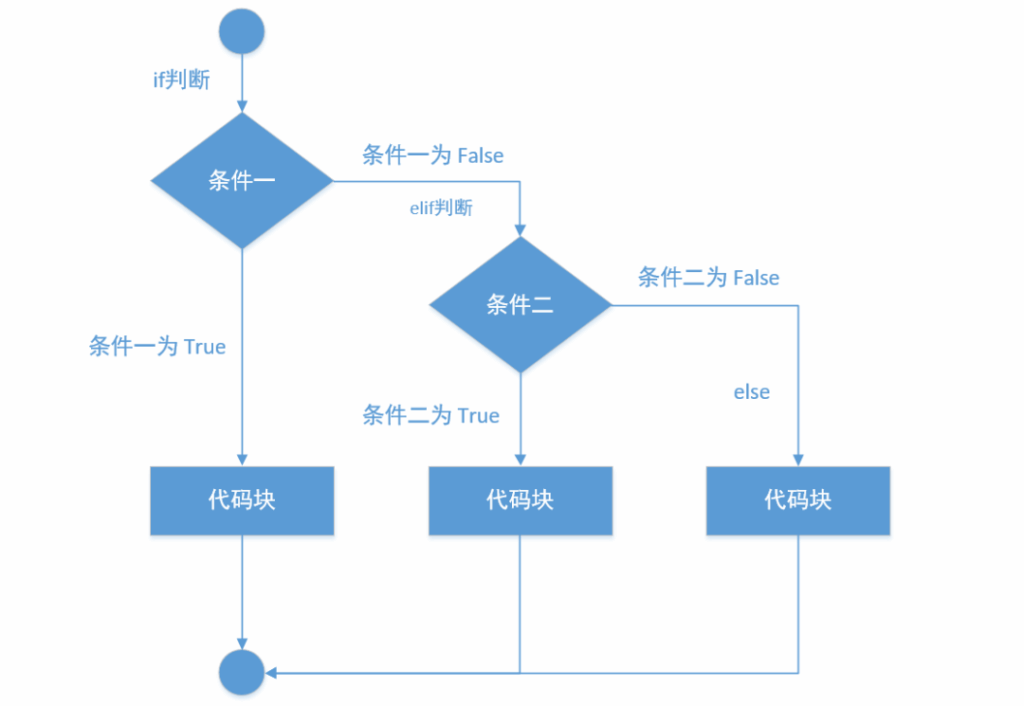
3. 多选一:if-elif-else
如果我们的选择不止两个呢?比如成绩评级:优秀、良好、及格、不及格。这时就需要 if-elif-else 结构。elif 是 else if 的缩写。
# 示例:根据分数评定等级
score = 88
if score >= 90:
print("等级:优秀")
elif score >= 80:
print("等级:良好")
elif score >= 60:
print("等级:及格")
else:
print("等级:不及格")
# 输出: 等级:良好程序会从上到下依次检查 if 和 elif 的条件,一旦遇到第一个满足的,就会执行对应的代码块,然后整个结构就结束了,后面的条件将不再被检查。
4. 组合拳:逻辑运算符 and, or, not
在做练习时,你可能会遇到更复杂的情况:需要同时满足两个条件,或者满足其中一个即可。这时我们需要逻辑运算符来帮忙。
- and (与):两边的条件都必须为真,结果才为真。
- 场景:检查一个年份是否是闰年(需同时被4整除且不能被100整除)。
- or (或):两边的条件只要有一个为真,结果就为真。
- 场景:在这个路口左转或者右转都可以到达目的地。
- not (非):把真变假,把假变真。
# 示例:检查数字是否能同时被5和7整除
num = 35
# 只有当 num%5==0 和 num%7==0 同时成立时,才会执行 print
if num % 5 == 0 and num % 7 == 0:
print(f"数字 {num} 可以同时被 5 和 7 整除")2. 让程序学会“重复”——循环
循环,顾名思义,就是让一段代码重复执行。Python主要有两种循环方式:for 循环和 while 循环。
1. for 循环:明确次数的重复
如果你明确知道要重复多少次,或者需要挨个处理一个集合里的所有元素,for 循环是最佳选择。
它最常和 range() 函数一起使用。range() 其实很强大,它有三种用法:
- range(5): 生成 0 到 4。
- range(1, 101): 生成 1 到 100(注意:顾头不顾尾,不包含结束值)。
- range(1, 100, 2): 步长(Step)模式。从1开始,每次增加2,直到100。这在求奇数/偶数时非常有用。
# 示例1:打印5次“Hello, Python!”
for i in range(5):
print(f"第{i+1}次打印: Hello, Python!")
# 示例2:打印 100 以内的奇数
print("100以内的奇数:")
for i in range(1, 100, 2): # 从1开始,每次跳2步:1, 3, 5...
print(i)1.1 这个也很重要:遍历字符串
for 循环不仅能数数,还能直接处理文字。如果你想检查一个单词里的每一个字母,可以直接让 for 循环遍历字符串。
# 示例:统计一句话里有多少个大写字母 'A'
text = "Apple and Ant"
count = 0
for char in text: # char 会依次代表 "A", "p", "p", "l", "e"...
if char == 'A':
count = count + 1
print(f"发现 {count} 个 A")2. while 循环:满足条件的重复
如果你不知道要重复多少次,只知道在什么条件下应该停止,那么 while 循环更适合。
它的逻辑是:只要某个条件一直成立(为 True),就一直重复执行循环内的代码。
# 示例:一张0.08毫米的纸,对折多少次可以超过珠穆朗玛峰的高度(约8848米)?
# 这是一个典型的不知道循环次数,只知道停止条件的场景
paper_thickness = 0.08 # 单位:毫米
everest_height = 8848 * 1000 # 转换为毫米
count = 0 # 记录对折次数
while paper_thickness < everest_height:
paper_thickness = paper_thickness * 2 # 每折一次,厚度翻倍
count = count + 1 # 次数加一
print(f"需要对折 {count} 次。")特别重要:在 while 循环内部,一定要有能够改变判断条件的语句(比如 count = count + 1),否则条件将永远为 True,程序就会陷入“无限循环”。
3. 循环的“微调”——break 和 continue
有时候,我们想在循环没有正常结束时提前退出,或者跳过某一次循环,这时就需要 break 和 continue。
break:紧急停止break用于完全终止并跳出当前所在的整个循环。# 示例:在一个列表中寻找数字 7,找到就停止 numbers = [1, 4, 9, 7, 12, 15] for num in numbers: print(f"正在检查: {num}") if num == 7: print("找到了数字 7,循环结束!") break # 立即跳出 for 循环continue:跳过此轮continue用于结束本次循环,跳过continue后面的代码,直接进入下一次循环。# 示例:打印1到10之间所有的奇数 for i in range(1, 11): if i % 2 == 0: # 如果是偶数 continue # 跳过本次循环,不执行下面的 print print(i)
四、列表、元组和集合
想象一下,你在整理房间。有些东西需要放进一个可以随时增减物品的抽屉里,有些珍贵的东西要放进一个上了锁、不能轻易改动的保险箱,还有些东西你只想保留一份,不要重复的,就像收藏邮票一样。
在 Python 中,我们也有三种类似的“盒子”来存放数据,它们就是我们今天的主角:列表 (List)、元组 (Tuple) 和 集合 (Set)。
1. 列表 (List):最灵活的数据抽屉
列表是 Python 里最常用、最灵活的数据容器。你可以把它想象成一个购物清单,随时可以往上加东西,也可以划掉买过的东西。
特点总结:
- 有序的:你放进去的顺序是固定的。
- 可变的 (mutable):可以随时添加、删除或修改里面的元素。
- 可重复的:可以存放多个相同的元素。
怎么创建和基本操作?
用方括号 [] 就可以创建一个列表。
# 创建一个包含不同类型元素的列表
my_list = [3.14, "Hello World", 123, [1, 2, 3]]
print(my_list)
# 输出: [3.14, 'Hello World', 123, [1, 2, 3]]像高手一样访问和修改元素(索引与切片):
Python 的索引不仅可以从头数,还可以从尾巴数,甚至可以切下一块。
# 1. 正向索引(从 0 开始)
print(my_list[1]) # 访问第二个元素 -> 'Hello World'
# 2. 修改元素(直接赋值)
my_list[0] = 99.9 # 把第一个元素改成 99.9
# 3. 负数索引(倒着数)
# -1 代表最后一个,-2 代表倒数第二个,以此类推
print(my_list[-1]) # 访问最后一个元素 -> [1, 2, 3]
# 4. 切片 Slicing(切取一部分)
# 格式:[起始:结束],包含起始,不包含结束
numbers = [10, 20, 30, 40, 50, 60]
print(numbers[1:4]) # 取索引1到3 -> [20, 30, 40]
print(numbers[:3]) # 从头取到索引2 -> [10, 20, 30]
print(numbers[::-1]) # 一个常用技巧:列表反转 -> [60, 50, 40, 30, 20, 10]像整理抽屉一样管理列表:
- 添加东西
append(): 在列表末尾添加一个。insert(): 在指定位置插队。+号:把两个列表拼起来(Concatenate)。
- 拿走东西
remove(): 删除第一个出现的指定值。pop(): 移除并返回指定索引的元素(不填索引默认移走最后一个)。
gene_list = ['ACTB', 'GAPDH', 'TP53']
# 添加
gene_list.append('PTEN')
gene_list.insert(1, 'MAPT')
# 拼接列表
extra_genes = ['MYC', 'EGFR']
full_list = gene_list + extra_genes
# 删除
gene_list.remove('GAPDH')
removed_item = gene_list.pop(1) # 移走索引1的元素列表的数据分析工具箱:
做作业时,你经常需要统计列表里的数据,Python 自带了很多好用的函数:
scores = [85, 92, 78, 92, 60]
# 1. 查长度 len()
print(len(scores)) # 输出: 5
# 2. 找极值和求和 max(), min(), sum()
print(max(scores)) # 最大值 -> 92
print(min(scores)) # 最小值 -> 60
print(sum(scores)) # 总和 -> 407
# 求平均值的小技巧:
average = sum(scores) / len(scores)
# 3. 计数 count()
print(scores.count(92)) # 92 出现了几次? -> 2
# 4. 排序 sort() vs sorted() —— 这里很容易晕!
# 方法A: list.sort() -> 直接修改原列表
scores.sort()
print(scores) # 原列表变成了 [60, 78, 85, 92, 92]
# 方法B: sorted(list) -> 原列表不动,返回一个新的排序列表
new_scores = sorted(scores, reverse=True) # 倒序排一个很酷的技巧:列表推导式 (List Comprehension)
这是一种非常 Pythonic 的、用一行代码创建列表的方式,简洁又高效。
# 创建一个包含 1 到 7 的平方数的列表
squares = [x**2 for x in range(1, 8)]
print(squares) # 输出: [1, 4, 9, 16, 25, 36, 49]2. 元组 (Tuple):不可改变的保险箱
元组和列表非常像,唯一的、也是最重要的区别是:元组一旦创建,就不能被修改。它就像一个锁上的保险箱,里面的东西安全可靠。
特点总结:
- 有序的:和列表一样。
- 不可变的 (immutable):创建后不能增、删、改。
- 可重复的:和列表一样。
怎么创建和使用?
用圆括号 () 来创建元组。
# 创建一个元组
my_tuple = ("H2O", 18, "水")
print(my_tuple[0]) # 访问 -> 'H2O'
# 尝试修改元组,会报错!
# my_tuple[1] = 20 # TypeError: 'tuple' object does not support item assignment实战场景:列表里装元组
在处理数据时(比如练习题里的学生成绩单或颜色代码),我们经常会遇到“列表里套元组”的情况。
# 一个包含 (名字, 分数) 的列表
students = [('Tom', 85), ('Jerry', 92), ('Anna', 78)]
# 想要找到 Jerry 的分数?我们可以遍历它
for student in students:
# student 现在是 ('Tom', 85) 这种元组
if student[0] == 'Jerry':
print(f"Jerry 的分数是: {student[1]}")3. 集合 (Set):独一无二的收藏夹
集合是一个很特别的容器,它只关心一件事:里面的东西是不是独一无二的。它就像一个邮票收藏夹,每种邮票只放一张。
特点总结:
- 无序的:元素没有固定的顺序,你不能通过索引(比如
[0])访问。 - 唯一的:自动去除所有重复的元素。
怎么创建和使用?
用花括号 {} 来创建集合。
# 创建一个集合,重复的'a'会被自动去掉
my_set = {'a', 'b', 'c', 'a'}
print(my_set)
# 输出: {'c', 'b', 'a'} (注意顺序可能不同)集合的超能力:
- 快速去重
这是集合最常见的用途,不仅能给列表去重,还能给字符串去重。
# 给列表去重
some_list = [1, 2, 2, 3]
unique = list(set(some_list)) # 转成集合去重,再转回列表
# 【新增】给字符串去重(练习题常用)
word = "apple"
unique_chars = set(word)
print(unique_chars) # 输出可能是 {'p', 'e', 'a', 'l'}- 数学运算
集合可以轻松地进行交集、并集、差集等运算。
set_a = {1, 2, 3, 4}
set_b = {3, 4, 5, 6}
print(set_a & set_b) # 交集 (都有的): {3, 4}
print(set_a | set_b) # 并集 (所有的): {1, 2, 3, 4, 5, 6}
print(set_a - set_b) # 差集 (a有b没有): {1, 2}五、数据结构与错误处理
本章来梳理一下 Python 基础中非常关键的两个部分:一种强大的数据类型——字典 (Dictionary),以及让我们的程序变得更健壮的错误与异常处理 (Error and Exception Handling)。此外,我们要补充一些列表操作的“组合拳”,这在处理实际问题(比如打分系统)时非常有用。
Python的数据“收纳盒”
在 Python 中,我们有几种用来存放多个数据的“收纳盒”,官方称之为数据集合 (Data Collections)。我们先快速回顾一下:
- 列表 (List):有序、可变、可重复。就像一个购物清单,可以随时添加、删除或修改。
my_list = [3.14, "你好", 123] - 元组 (Tuple):有序、不可变、可重复。就像一份签了字的合同,内容一旦确定就不能改了。
my_tuple = ("水", 18) - 集合 (Set):无序、可变、不重复。就像一个班级的学生名单,每个学生都是独一无二的。
my_set = {'a', 123, 3.14}
今天的主角是第四种,也是功能最强大的收纳盒之一。
1. 深入理解字典 (Dictionary)
想象一下一本真正的字典,我们通过拼音(比如 'píng guǒ')来查找它的释义(苹果)。Python 的字典 (dictionary) 也是这个原理,它通过一个 “键” (key) 来查找对应的 “值” (value)。
1. 字典长什么样?
我们用花括号 {} 来创建字典,里面包含若干个 key: value 对,用逗号隔开。
# 一个存储氨基酸缩写的字典
aa_name = { 'A':'Ala', 'C':'Cys', 'E':'Glu' }
print(aa_name)
# 输出: {'A': 'Ala', 'C': 'Cys', 'E': 'Glu'}2. 字典的基本操作
- 访问值 (Read):通过
key来获取value。print(aa_name['C']) # 输出: 'Cys'
注意:如果 key 不存在,程序会报错 (KeyError)。 - 添加或更新 (Create / Update):如果 key 不存在,就添加;如果已存在,就更新它的 value。
# 添加一个新的键值对 aa_name['K'] = 'Lys' # 更新一个已有的值 aa_name['A'] = 'Alanine' - 删除 (Delete):使用
del关键字。del aa_name['E']
3. 字典的“规矩”
- 键 (Key):必须是不可变的类型,比如字符串、数字或元组。列表是可变的,所以不能当做 key。同时,key 必须是唯一的。
- 值 (Value):可以是任何数据类型(数字、字符串、列表、甚至另一个字典),也可以重复。
4. 实用技巧:两个列表变字典
有时候我们会遇到两个分开的列表,一个是名字,一个是分数,想把它们合成为一个字典。我们可以使用 zip 这个小工具。
names = ["Rash", "Kil", "Varsha"]
values = [1, 4, 5]
# zip像拉链一样把两个列表咬合在一起,dict再把它转为字典
my_dict = dict(zip(names, values))
print(my_dict) # {'Rash': 1, 'Kil': 4, 'Varsha': 5}5. 一些实用的字典方法
.get(key, default_value):安全地获取值。如果 key 不存在,它不会报错,而是返回你指定的默认值。# 'X' 这个键不存在
value = aa_name.get('X', '未知氨基酸')
print(value)
# 输出: '未知氨基酸'.keys()/.values()/.items():分别获取所有的键、值、以及键值对。这在循环中特别好用:
#遍历所有的键值对
for short_name, full_name in aa_name.items():
print(f"{short_name} 的全称是 {full_name}")
6. 经典实战模式
在完成作业时,你经常会遇到以下两种情况,需要熟练掌握:
- 模式一:频率统计(统计字母/单词出现的次数)
逻辑是:如果在字典里没见过这个字符,就新建记录设为1;如果见过了,就在原有的数字上加1。
text = "hello"
counts = {}
for char in text:
if char in counts:
counts[char] += 1 # 只要是数字,就可以做加减
else:
counts[char] = 1 # 第一次遇见
print(counts) # {'h': 1, 'e': 1, 'l': 2, 'o': 1}- 模式二:值是一个列表(分类归纳)
有时候一个键对应多个数据(比如“成绩A”对应“三个学生的学号”)。这时字典的 value 就应该是一个列表。
grades = {'101': 'A', '102': 'B', '103': 'A'}
grade_book = {}
for sid, grade in grades.items():
if grade not in grade_book:
grade_book[grade] = [] # 如果这个成绩还没记录过,先创建一个空列表
grade_book[grade].append(sid) # 把学号追加进去
print(grade_book) # {'A': ['101', '103'], 'B': ['102']}
- 模式三:给字典排序
字典本身是无序的,但如果我们想按“分数高低”打印名字,需要把它转化成列表排序。
scores = {'Alice': 88, 'Bob': 95, 'Cat': 70}
# 使用 sorted 函数,key参数是排序的依据
# x[1] 表示按照值(分数)排,reverse=True 表示从大到小
ranked = sorted(scores.items(), key=lambda x: x[1], reverse=True)
print(ranked) # [('Bob', 95), ('Alice', 88), ('Cat', 70)]
补充:列表操作的小贴士
在处理打分题目时,你可能需要对列表里的数字进行切片和统计,这里补充几个关键点:
- 排序:
my_list.sort()会直接改变列表顺序。 - 切片 (Slicing):去掉头尾可以使用
[1:-1]。意思是:从第2个元素开始取,取到倒数第2个。 - 求和与长度:
sum(my_list)求总和,len(my_list)求个数。
scores = [9, 5, 8, 10, 6]
scores.sort() # 变成 [5, 6, 8, 9, 10]
valid_scores = scores[1:-1] # 去掉最低(5)和最高(10),得到 [6, 8, 9]
avg = sum(valid_scores) / len(valid_scores)2. 错误与异常处理
代码很少一次就能完美运行,出错是常态。当程序遇到无法处理的情况时,就会抛出一个异常 (Exception),然后程序就“崩”了。学会处理异常,是写出可靠程序的关键。
1. 主动“报警”:raise
有时候,我们希望在特定条件下,程序能主动停止并告诉我们哪里出了问题。这时就可以用 raise 来手动抛出一个异常。
def divide(a, b):
if b == 0:
# 主动抛出错误,防止系统崩溃得不明不白
raise ValueError("分母不能为零!")
return a / b2. 从容“接招”:try…except
如果我们预感到某段代码可能会出错,但又不希望它导致整个程序崩溃,就可以用 try...except 把它“包”起来。

它的逻辑是:
- try:尝试执行这里的代码。
- except:如果 try 里的代码出错了,就执行这里的代码来“补救”,然后程序继续往下走。
user_input = input("请输入一个数字: ")
try:
number = int(user_input)
print(f"你输入的数字是: {number}")
except ValueError:
# 如果转换失败 (比如输入了'abc')
print("输入无效,请输入一个真正的数字!")3. 捕获特定的异常
有时候我们想对不同的错误做不同的处理,比如“输入文字”和“除以零”应该是两种提示。我们可以写多个 except。
try:
a = int(input("A: "))
b = int(input("B: "))
print(a / b)
except ValueError:
print("错误:请输入数字!") # 处理非数字输入
except ZeroDivisionError:
print("错误:不能除以零!") # 处理除数为04. 终极组合:死循环 + 异常捕获
这是最常用的模式,用来强制用户输入正确的数据。如果不正确,就一直问,直到正确为止。
numbers = []
print("请输入5个整数:")
while len(numbers) < 5:
user_input = input("请输入数字: ")
try:
num = int(user_input) # 尝试转换
numbers.append(num) # 如果成功,加入列表
except ValueError:
print("这不是整数,请重试。") # 如果失败,提示并进入下一次循环
print("录入完成:", numbers)5. 无论如何都要执行:finally
try...except 还有两个可选的搭档:
else:如果 try 块没有发生任何异常,就会执行 else 里的代码。finally:无论是否发生异常,finally 里的代码总会被执行,通常用来做一些清理工作(比如关闭文件)。
六、Python 输入与输出
一个只会自己埋头计算,却不与外界交流的程序,就像一个在孤岛上自言自语的人,没什么实际用处。程序需要接收我们的指令和数据(输入),也需要将计算结果告诉我们(输出)。
1. 与用户的直接对话:标准输入与输出
最直接的交流方式,就是通过键盘和屏幕。
1.接收用户的输入:input()
当你需要用户提供一些信息时,比如姓名、年龄或者一个数字,就可以使用 input() 函数。
它的用法很简单:
# input() 会暂停程序,等待用户输入内容,然后按回车
# [prompt] 是可选的提示语,告诉用户该输入什么
变量名 = input("提示语")核心要点: 无论用户输入的是数字还是文字,input() 函数收到的永远是字符串 (str) 类型。
# 示例:一个简单的个人信息录入程序
name = input("请输入你的名字: ")
age_str = input("请输入你的年龄: ")
# 如果我们想对年龄进行计算,必须先把它从字符串转成整数
age_int = int(age_str)
print(f"你好, {name}!")
print(f"明年你就 {age_int + 1} 岁了。")2. 向屏幕展示结果:print()
print() 函数我们已经很熟悉了,但这里介绍两种更优雅的格式化输出方式,让你的输出内容更清晰。
- f-string (推荐):在字符串前面加一个
f,然后用花括号{}包裹变量名。这种方式直观、简洁。
country = "中国"
city = "上海"
# 使用 f-string
print(f"我住在{country}的{city}。")
# 输出: 我住在中国的上海。2. 理解数据的大本营:文件与路径
当数据量很大,或者需要永久保存时,我们就不能只依赖键盘输入了,而是要把数据存放在文件 (File) 中。
1. 两种文件类型:文本文件 vs. 二进制文件
- 文本文件 (Text File):里面存的是字符,就像一个记事本。我们可以用记事本、VS Code 等文本编辑器直接打开阅读和编辑。常见的如
.txt,.py,.csv文件。 - 二进制文件 (Binary File):里面存的是计算机才能直接理解的字节数据。如果你用记事本强行打开,看到的就是一堆乱码。常见的如图片 (
.jpg)、视频 (.mp4)、Word文档 (.docx)。
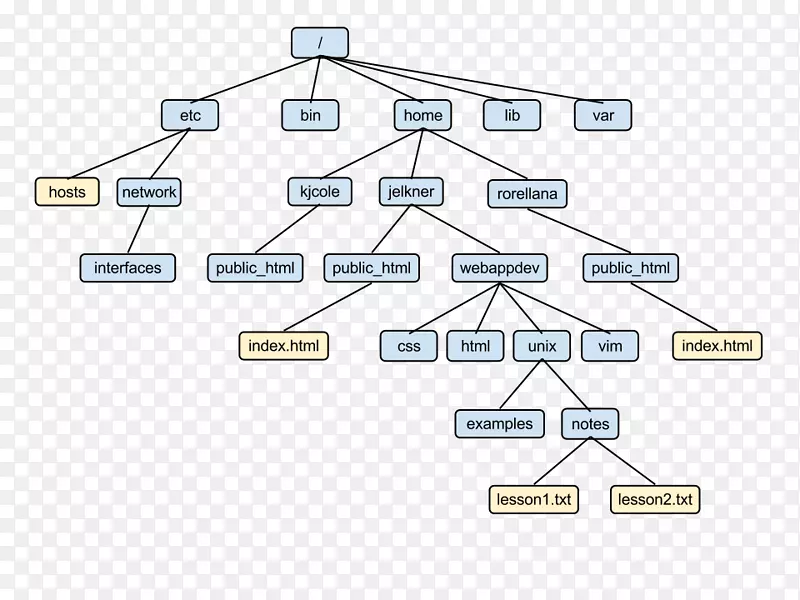
2. 找到你的文件:目录与路径
文件都存放在目录 (Directory)(也就是我们常说的文件夹)里。为了找到一个文件,我们需要它的“地址”,这个地址就是路径 (Path)。
- 绝对路径 (Absolute Path):从电脑的根目录开始的完整路径。它独一无二,无论你在哪里运行程序,都能指向同一个位置。
- Windows 示例:
C:\Users\Admin\Documents\data.txt - Mac/Linux 示例:
/Users/admin/Documents/data.txt
- Windows 示例:
- 相对路径 (Relative Path):从你当前程序运行的位置开始的路径。它更灵活,但会随着你运行程序的地点而改变。
./data.txt或data.txt:表示当前目录下的data.txt文件。../data.txt:表示上一级目录中的data.txt文件。
3. Python 的文件管理能力:os 模块
Python 的 os 模块就像一个文件系统总管,能帮你执行很多文件和目录操作。
这里介绍几个最常用的功能:
os.getcwd(): 获取当前的工作目录。os.listdir(): 查看一个目录里有哪些文件和文件夹。os.path.join(): 强烈推荐! 拼接路径。它会自动使用你当前操作系统正确的路径分隔符(\或/),避免了跨平台问题。
import os
# 获取并打印当前工作目录
current_dir = os.getcwd()
print(f"我当前在: {current_dir}")
# 使用 os.path.join 智能地拼接路径
file_path = os.path.join(current_dir, 'data', 'my_file.txt')
print(f"我想要操作的文件路径是: {file_path}")4. 核心技能:读写文件
这是本节课的重头戏。文件操作的基本流程是“打开 -> 读/写 -> 关闭”。
1. 打开文件:open()
open() 函数会返回一个“文件句柄”,你可以通过它来操作文件。
open(文件路径, 模式)
- 模式 (mode) 决定了你想怎么操作文件,最常用的有:
'r': 读 (Read)。默认模式,如果文件不存在会报错。'w': 写 (Write)。如果文件不存在会创建;如果存在,会清空原有内容再写入。'a': 追加 (Append)。在文件末尾添加内容,不会清空原有内容。
2. 最佳实践:with 语句
手动 close() 文件很麻烦,还容易忘记。Python 提供了一个绝佳的工具 with 语句,它能保证在代码块执行完毕后,自动、安全地关闭文件,即使中途发生错误也不例外。
这是操作文件的标准姿势,请务必掌握!
3. 读取文件内容处理
读取文件不仅仅是把内容拿出来,通常还需要对字符串进行“清洗”和“切割”。
(1)逐行读取与清洗
这是最常用的方式,适合处理大文件。
file_path = 'haiku.txt'
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
# 【重点】rstrip():仅仅去除行尾的换行符 \n,保留左边的缩进
clean_line = line.rstrip()
# 【重点】replace():替换字符,比如把句号去掉
# 语法:字符串.replace("旧字符", "新字符")
no_dot_line = clean_line.replace(".", "")
# 【重点】split():把句子切成单词列表
# 默认按空格切割,返回一个列表,比如 ['Explicit', 'is', 'better']
words = no_dot_line.split()
print(words)
except FileNotFoundError:
print(f"错误:找不到文件 {file_path}")(2)一次性读取
如果你文件很小,或者想对整个文件的内容做统一替换(比如把里面所有的 # 号删掉),可以用 .read()。
with open('code.py', 'r') as f:
content = f.read() # 将整个文件读成一个巨大的字符串
# 直接替换整个字符串里的内容
new_content = content.replace("#", "")
print(new_content)4. 写入文件
write() 方法不会自动添加换行,需要我们手动加入 \n。此外,如果你在处理表格数据(比如 Excel 或 CSV 数据),还常用到制表符 \t。
# 假设我们有一个字典,想把它存成表格形式
codon_dict = {'ATA': 'I', 'ATC': 'I', 'GCA': 'A'}
output_file = 'codon_table.txt'
with open(output_file, 'w', encoding='utf-8') as f:
for key, value in codon_dict.items():
# 【重点】使用 \t (Tab键) 来分隔列,使用 \n 来换行
# 写入格式:密码子 [Tab] 氨基酸 [换行]
f.write(f"{key}\t{value}\n")
print(f"表格已保存到 {output_file}")
5. 特殊工具:用 pickle 保存 Python 对象
有时我们想保存的不是简单的文本,而是一个复杂的 Python 对象,比如一个列表、一个字典,甚至是自己创建的类的实例。当程序关闭后,这些内存中的变量就消失了。
pickle 模块就是为此而生。它可以将 Python 对象序列化 (Serialization) 成一个字节流,存入文件;之后再从文件中读取,反序列化恢复成原来的对象。
pickle.dump(obj, file): 将对象obj存入文件。pickle.load(file): 从文件中加载对象。
注意:pickle 文件是二进制文件,所以打开模式必须包含 'b' (binary),即 'wb' (写二进制) 或 'rb' (读二进制)。
import pickle
# 假设我们有一个复杂的数据结构
user_profile = {
'id': 101,
'name': 'Alice',
'courses': ['Math', 'Physics', 'Python'],
'is_active': True
}
# 1. 使用 pickle.dump 保存对象
with open('profile.pkl', 'wb') as f:
pickle.dump(user_profile, f)
print("用户配置已保存。")
# 2. 使用 pickle.load 加载对象
with open('profile.pkl', 'rb') as f:
loaded_profile = pickle.load(f)
print("用户配置已加载。")
print(loaded_profile)
# 验证加载回来的对象和原来的一样
print(loaded_profile['courses'])安全警告:pickle 很强大,但也很危险。绝对不要加载来自不信任来源的 pickle 文件,因为它可能包含恶意代码。
七、Python 函数
1. 为什么我们需要函数?
想象一下,你在写一个很长的程序,里面有几处都需要计算一个数的平方。最笨的办法是每次都写一遍 x * x。如果以后想改成计算立方,你就得找遍所有代码去修改,非常麻烦。
函数就是为了解决这个问题而生的。它允许你将一段具有特定功能的代码打包,并给它起一个名字。之后,你只需要通过这个名字就可以随时随地“调用”这段代码。
这带来了三个核心好处:
- 模块化 (Modularity):让复杂的程序变得像搭积木一样,清晰明了。
- 可复用性 (Re-usability):一次编写,多次使用。
- 可维护性 (Maintainability):修改功能时,只需修改函数本身,所有调用它的地方都会同步更新。
2. 创建并调用你的第一个函数
创建自己的函数(即用户自定义函数)非常简单,只需要记住固定的格式。
基本语法:
def function_name(parameter1, parameter2):
"""
这里是文档字符串(docstring),用于解释函数的功能。
"""
# 函数体代码(需要缩进)
# ...
return value # 可选,用于返回结果我们来分解一下:
def:关键字,告诉 Python “我要定义一个函数了”。function_name:你给函数起的名字,最好能描述它的功能(例如calculate_area)。(parameter1, parameter2):参数列表,是函数需要接收的外部数据。return:可选,用于将函数处理的结果返回给调用者。没有 return 的函数会自动返回None。
示例1:简单的打印函数(无返回值)
有些函数只负责“做动作”,不需要“给回应”。
def say_hello(name):
print(f"你好, {name}!")
# 调用函数
say_hello("小明")
# 控制台直接显示:你好, 小明!示例2:带返回值的计算函数
大多数时候,我们需要函数计算出一个结果,并在后续代码中使用这个结果,这时必须用 return。
def get_square(number):
"""计算并返回一个数的平方"""
result = number * number
return result
# 调用函数,必须用一个变量去“接住”它的返回值
my_num = get_square(5)
print(f"计算结果是: {my_num}")
# 输出: 计算结果是: 25新手易错点:return才是把结果交还给程序。如果你在练习题中看到“return the result”,请务必使用return。
3. 灵活多变的参数
函数的参数是它与外部世界沟通的桥梁,Python 提供了非常灵活的参数传递方式。
- 位置参数 (Positional Arguments)
最常见的方式,实参的顺序与形参的顺序一一对应。def describe(animal, name): ...
调用describe("猫", "咪咪"),“猫”对应animal。 - 关键字参数 (Keyword Arguments)
通过参数名=值的形式传递,可以忽略参数的顺序。describe(name="咪咪", animal="猫") - 默认值参数 (Default Arguments)
在定义函数时,可以给参数一个默认值。def greet(name, msg="你好"): print(f"{msg}, {name}") greet("小红") # 输出: 你好, 小红 greet("小明", "早安") # 输出: 早安, 小明
4. 变量的作用域 (Scope)
变量不是在程序的任何地方都可以被访问的,它存在一个“作用域”。
- 局部变量 (Local Variable):在函数内部定义的变量,出了函数就“死”了,外面访问不到。
- 全局变量 (Global Variable):在所有函数外部定义的变量,大家都能读。
x = 10 # 全局变量
def my_function():
y = 5 # 局部变量
print(x) # 可以读取全局变量
print(y) # 可以读取局部变量
my_function()
# print(y) # 如果在这里运行这行,会报错,因为 y 已经在函数结束时销毁了。5. 进阶:函数与数据结构
在实际编程题中,函数不仅处理简单的数字,经常需要处理列表 (List) 或 字典 (Dictionary)。
场景一:传入两个列表进行计算
编写函数时,可以通过循环遍历列表的索引来同时处理两个列表的数据。这在计算向量点积等数学问题时很常见。
def calculate_sum_lists(list_a, list_b):
"""计算两个列表中对应元素的和"""
total = 0
# 假设两个列表长度一样,使用 range(len()) 遍历
for i in range(len(list_a)):
val_a = list_a[i]
val_b = list_b[i]
total = total + (val_a + val_b)
return total
nums1 = [1, 2, 3]
nums2 = [4, 5, 6]
print(calculate_sum_lists(nums1, nums2)) # 输出 21场景二:将列表转换为字典
函数也可以接收列表,并在内部构建一个新的字典返回。
def create_info_dict(names, ages):
result_dict = {} # 创建空字典
for i in range(len(names)):
key = names[i]
value = ages[i]
result_dict[key] = value # 存入字典
return result_dict
n = ["Alice", "Bob"]
a = [20, 25]
print(create_info_dict(n, a)) # 输出 {'Alice': 20, 'Bob': 25}6. 辅助函数:拆解复杂逻辑
当一道题目要求很复杂时,最好的办法是分而治之。我们可以写一个“辅助函数”来处理小的逻辑,再写一个“主函数”来调用它。
例子:检查快乐数
题目可能要求:1. 算各位平方和;2. 判断是否最终为1。
# 辅助函数:只做一件事,计算各位数字的平方和
def sum_squares(n):
total = 0
s_n = str(n) # 转成字符串方便取每一位
for digit in s_n:
total += int(digit) ** 2
return total
# 主函数:利用上面的工具解决问题
def check_happy(n):
current = n
# 简单模拟检查过程(实际题目可能需要防止死循环)
while current != 1:
current = sum_squares(current) # 调用辅助函数
if current == 4: # 快乐数的数学特性:如果变到4就是死循环,不是快乐数
return False
return True这种写法让代码逻辑非常清晰,也是练习题中常考的模式。
7. 递归 (Recursion)
递归就是函数自己调用自己。它通常包含两个部分:
- 基线条件 (Base Case):什么时候停止(比如
n==0或n==1)。 - 递归步骤:将问题规模缩小,继续调用自己。
# 计算阶乘的例子
def factorial(n):
if n == 1: # 基线条件
return 1
else: # 递归步骤
return n * factorial(n - 1)提示:斐波那契数列 (Fibonacci) 的递归写法类似,只是它有两个基线条件 n=0 和 n=1,且每次需要调用两次自己 f(n-1) + f(n-2)。
8. 匿名函数 (Lambda) 与 模块 (Module)
- Lambda:一种没有名字的单行迷你函数。
add = lambda x, y: x + y - 模块:将函数保存在
.py文件中,通过import引用,方便管理大型项目。
八、NumPy与SciPy
在处理大量数据,尤其是数字时,Python自带的列表(list)会显得有点慢。为了解决这个问题,NumPy应运而生。它提供了一种叫做array(数组)的东西,专门用来进行快速的数学运算。而SciPy则是在NumPy的基础上,提供了更多现成的科学计算工具。
这节课,我们就通过几个常见的课堂练习,把这两个库的核心用法给捋清楚。
1. NumPy:数据处理的基石
NumPy是科学计算的基础,几乎所有的数据分析工具都离不开它。我们先从它的核心——数组(array)开始。
1. 创建与切片:不只是随机数
要分析数据,首先得有数据。NumPy除了生成随机数,还能生成各种“初始状态”的矩阵,并且我们可以像切蛋糕一样精准地选中我们需要的部分。
比如,创建一个全是0的矩阵,或者全是1的矩阵:
import numpy as np
# 创建一个8x8的全0矩阵
# dtype=int 表示我们希望里面是整数,而不是浮点数
zeros_arr = np.zeros((8, 8), dtype=int)
print("全0矩阵:")
print(zeros_arr)切片(Slicing)是NumPy的灵魂。它的格式通常是 [开始:结束:步长]。
如果想给这个矩阵做个“棋盘”图案(隔一个数填一个1),我们可以利用步长:
# [1::2] 表示从索引1开始,每隔2个取一个
# [::2] 表示从索引0开始,每隔2个取一个
# 这里的操作有点像坐标定位:把特定位置的0变成1
zeros_arr[1::2, ::2] = 1
zeros_arr[::2, 1::2] = 1
print("棋盘图案矩阵:")
print(zeros_arr)当然,生成随机数依然是常用操作:
# 创建一个5x5的随机数组
arr = np.random.rand(5, 5)2. 数组的聚合与排序:快速了解数据全貌
拿到一大堆数据后,我们通常想知道它的整体情况,比如总和、平均值是多少,或者给它排个序。
# 还是用刚才的5x5数组 arr
# 1. 计算所有元素的总和
total_sum = arr.sum()
print(f"数组总和: {total_sum}")
# 2. 计算每一行的平均值
# axis=1 代表横向(行),axis=0 代表纵向(列)
row_means = arr.mean(axis=1)
print(f"每行的平均值: {row_means}")
# 3. 给数组排序
# 注意:np.sort 返回的是副本,不会打乱原数组
sorted_arr = np.sort(arr, axis=1) # 按行从小到大排序
print("按行排序后的数组:")
print(sorted_arr)3. 筛选与修改:给数据做个“手术”
这是NumPy最强大的功能之一:布尔索引(Boolean Indexing)。简单说,就是根据一个条件(真或假)来快速地选中或修改数据。
比如,我们想把数组 arr 里所有小于平均值的元素,都替换成平均值本身(这在数据清洗中很常见)。
# 1. 计算整个数组的平均值
mean_val = arr.mean()
# 2. 使用布尔索引,将小于平均值的元素替换掉
# 逻辑是:找到 arr < mean_val 的位置,赋值为 mean_val
arr[arr < mean_val] = mean_val
print("修正后的数组:")
print(arr)4. 线性代数:解方程组 【新增:解决练习4】
数学课上我们都要解方程组,比如:
3x + y = 9
x + 2y = 8
用手算很慢,用NumPy的线性代数模块(linalg)只需要两行代码。我们需要把方程写成矩阵形式 Ax = B。
# 系数矩阵 A
A = np.array([[3, 1], [1, 2]])
# 结果矩阵 B
B = np.array([9, 8])
# solve函数直接求解
solution = np.linalg.solve(A, B)
print(f"方程组的解: x={solution[0]}, y={solution[1]}")5. 条件赋值 np.where():更灵活的选择
有时候,我们的逻辑是“如果满足条件A,就赋值为X;否则,赋值为Y”。np.where() 就是做这个的。
一个经典的例子是随机游走(Random Walk)。假设一个人随机地向前或向后走,我们可以这样模拟他的每一步:
# 生成10个随机数
draws = np.random.random(10)
# 如果随机数大于等于0.5,记为向前走(1),否则向后走(-1)
steps = np.where(draws >= 0.5, 1, -1)
print(f"随机漫步的每一步: {steps}")2. SciPy:更专业的科学计算工具箱
如果说NumPy是提供了扳手和螺丝刀,那SciPy就是提供了一个装满了各种专业工具的工具箱。
求解定积分
在高等数学里,我们经常需要求解定积分。手动计算很麻烦,但用SciPy的 quad 函数就非常简单。
比如,我们要计算函数 \( f(x) = x^2 \) 在 [0, 1] 区间上的定积分( \( \int_0^1 x^2 dx \) )。
from scipy.integrate import quad
# 1. 定义我们想要求积分的函数
def my_function(x):
return x**2
# 2. 使用quad函数计算
# 参数分别是:函数名,积分下限,积分上限
result, error = quad(my_function, 0, 1)
print(f"定积分结果: {result}")3. 综合实战:数据分析初体验
理论学完了,我们来模拟一个真实的数据分析场景。假设我们有一份健康数据 health.csv,想分析一下高血压患者的特征,并构建一个回归方程。
这里我们通常会用到另一个神器——Pandas(处理表格),配合 SciPy 进行统计分析。
import pandas as pd
from scipy import stats
# 1. 读取数据 (假设目录下有这个文件)
# df = pd.read_csv('health.csv')
# 为了演示,我们先创建一个模拟的DataFrame
df = pd.DataFrame({
'年龄': [25, 30, 45, 50, 60],
'收缩压': [110, 120, 135, 140, 150],
'BMI': [20, 24, 29, 28, 31]
})
# 2. 查看数据的基本统计信息(均值、标准差、最大/最小值等)
# .describe() 是一个超级方便的函数,直接搞定所有统计指标
print(df.describe())
# 3. 简单筛选:计算肥胖率(BMI > 28)
obesity_rate = (df['BMI'] > 28).mean()
print(f"肥胖率: {obesity_rate:.2%}")
# 4. 构建线性回归方程:探索“年龄”和“收缩压”的关系
# 我们想找到直线 y = kx + b (其中 k 是斜率,b 是截距)
slope, intercept, r_value, p_value, std_err = stats.linregress(df['年龄'], df['收缩压'])
print(f"\n回归方程结果:")
print(f"斜率 (slope): {slope:.2f}")
print(f"截距 (intercept): {intercept:.2f}")
print(f"方程: 收缩压 = {slope:.2f} * 年龄 + {intercept:.2f}")
# 我们可以试着预测一下 40 岁时的收缩压:
prediction = slope * 40 + intercept
print(f"预测 40 岁时的收缩压: {prediction:.2f}")
这个练习告诉我们,在真实世界中,我们常常是 Pandas + NumPy + SciPy 组合出击,来完成从数据读取、清洗、统计到建模的全过程。
九、Pandas入门
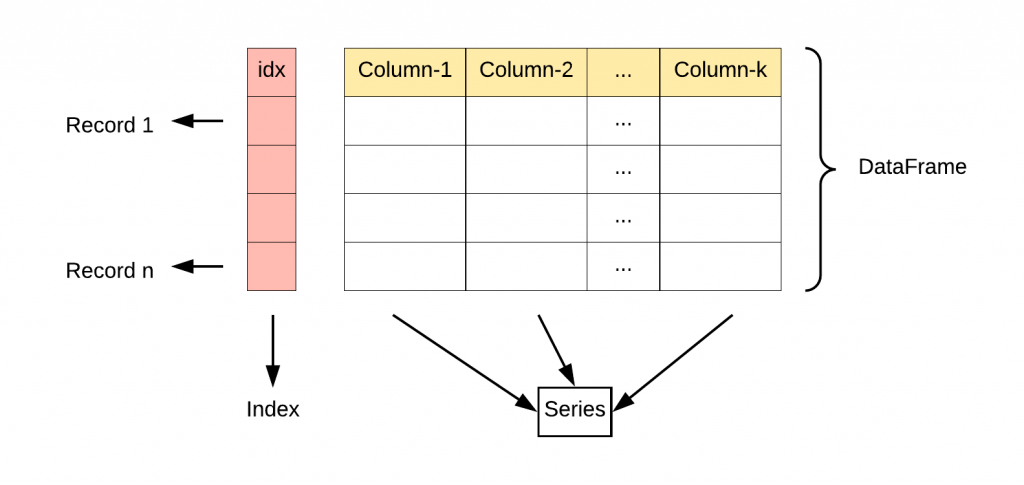
我们上一张之前学过 NumPy,你会发现 Pandas 的很多操作都似曾相识。没错,Pandas 就是站在 NumPy 这个巨人的肩膀上,为我们提供了更强大、更灵活的数据处理能力。简单来说,如果说 NumPy 让我们能处理数字“矩阵”,那么 Pandas 则让我们能处理带标签的、更像Excel表格的“数据表”。
Pandas 的两大核心:Series 和 DataFrame
Pandas 之所以强大,主要归功于它的两个核心数据结构:
- Series:可以理解为一个带标签的一维数组。
- DataFrame:可以理解为一个带标签的二维表格,也是我们最常用的。
我们先从简单的一维 Series 开始。
核心一:Series (一维数据)
Series 就像一个特殊的列表,它的特殊之处在于每个元素都有一个对应的“标签”,我们称之为索引 (index)。
1. 创建 Series
我们可以用列表、字典等来创建它。
- 从列表创建:
import pandas as pd
import numpy as np
# 创建一个最简单的 Series,索引会自动从 0 开始
s = pd.Series([10, 20, 30, 40])
print(s)输出:
0 10
1 20
2 30
3 40
dtype: int64- 从字典创建:
字典的键 (key) 会自动成为 Series 的索引 (index)。
data_dict = {'语文': 95, '数学': 100, '英语': 88}
s_scores = pd.Series(data_dict)
print(s_scores)输出:
语文 95
数学 100
英语 88
dtype: int642. 访问 Series 数据
访问 Series 的数据非常灵活,既可以像列表一样用数字位置,也可以像字典一样用索引标签。
# 使用位置
print(s_scores[1]) # 输出: 100
# 使用索引标签
print(s_scores['语文']) # 输出: 953. 自动对齐与数学运算
Pandas 非常智能,当两个 Series 进行运算时,它会自动对齐索引。此外,你可以直接对整个 Series 进行数学计算,不需要写循环。
s1 = pd.Series({'a': 1, 'b': 2, 'c': 3})
s2 = pd.Series({'b': 10, 'c': 20, 'd': 30})
# 自动对齐:a 在 s2 中没有,d 在 s1 中没有,结果为 NaN
print(s1 + s2)
# 数学运算:类似于 NumPy,直接批量操作
# 例如:将 s1 所有数值乘以 10
print(s1 * 10) 4. 简单的统计功能
Series 内置了很多方便的统计方法,帮你快速了解数据概况。
s.mean(): 计��平均值。s.max(): 获取最大值。s.idxmax(): 获取最大值对应的索引(比如哪一天温度最高)。
temps = pd.Series([20, 35, 30], index=['Mon', 'Tue', 'Wed'])
print(temps.mean()) # 输出: 28.33...
print(temps.max()) # 输出: 35
print(temps.idxmax()) # 输出: Tue (周二最热)核心二:DataFrame (二维数据)
DataFrame 是 Pandas 的主角。你可以把它想象成一张 Excel 表格,有行有列,而且行和列都有自己的标签(行标签叫 index,列标签叫 columns)。
1. 创建 DataFrame
最常见的方式是使用一个字典来创建,字典的键是列名,值是该列的数据列表。
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [20, 21, 22],
'专业': ['计算机', '物理', '化学']
}
df = pd.DataFrame(data)
print(df)输出:
姓名 年龄 专业
0 张三 20 计算机
1 李四 21 物理
2 王五 22 化学2. 从文件读取数据
在实际工作中,数据通常存储在文件里,比如 CSV 文件。用 Pandas 读取非常简单。
pd.read_csv() 是你必须掌握的函数。假设我们有一个 students.csv 文件。
# 假设有一个 students.csv 文件,内容如下:
# name,age,major
# Alice,20,Math
# Bob,22,History
# Charlie,21,Physics
# 读取文件
df_from_csv = pd.read_csv('students.csv')
# 查看数据的前5行
print(df_from_csv.head())read_csv 有很多重要参数,比如 sep (指定分隔符,默认为逗号), header (指定哪行为表头), index_col (指定哪列为行索引)。
3. 保存 DataFrame 到文件
同样,我们可以轻松地将处理好的数据保存为新文件。
# 假设我们给上面的 df 添加了一列
df['入学年份'] = [2020, 2019, 2019]
# 保存到新的 CSV 文件,index=False 表示不把行索引写入文件
df.to_csv('students_new.csv', index=False)4. 统计数据的频率
如果你想知道某一列中每个值出现了多少次(比如统计每个专业有多少人),使用 value_counts() 非常方便。
# 假设 '专业' 列有:计算机, 物理, 计算机
print(df['专业'].value_counts())
# 输出:
# 计算机 2
# 物理 1如何查看和选择数据?
拿到了数据表 (DataFrame),接下来就是怎么看、怎么选。
1. 基本查看
df.head(n): 查看前 n 行数据(默认 n=5)。df.tail(n): 查看后 n 行数据(默认 n=5)。df.shape: 查看数据的形状(行数, 列数)。df.columns: 查看所有列名。df.index: 查看所有行索引。
2. 选择列
像操作字典一样,使用方括号 []。有时候我们需要把一列数据拿出来当作普通的 Python 列表使用。
# 选择单列(结果是 Series)
ages = df['年龄']
# 将 Series 转换为 Python 列表 (覆盖 Practice 2)
ages_list = df['年龄'].tolist()
# 选择多列(结果是 DataFrame)
name_and_major = df[['姓名', '专业']]3. 选择行和单元格:.loc 与 .iloc
这是 Pandas 的精髓,也是初学者的一个难点。
.loc[]: 基于标签 (label) 进行选择。.iloc[]: 基于位置 (integer location) 进行选择,即第几行、第几列。
# 准备一个带自定义索引的 DataFrame
df.index = ['S01', 'S02', 'S03']
print(df)
# 姓名 年龄 专业 入学年份
# S01 张三 20 计算机 2020
# S02 李四 21 物理 2019
# S03 王五 22 化学 2019
# --- 使用 .loc (按标签) ---
# 选择 S02 这一行
print(df.loc['S02'])
# 选择 S03 这一行的'专业'
print(df.loc['S03', '专业']) # 输出: 化学
# --- 使用 .iloc (按位置) ---
# 选择第 1 行 (位置从0开始)
print(df.iloc[0])
# 选择第 2 行、第 1 列的单元格
print(df.iloc[2, 1]) # 输出: 224. 条件筛选
这是数据分析中最常用的操作。如果是多个条件,需要用 & (且) 或 | (或) 连接,并且每个条件都要用括号括起来。
# 条件筛选
older_students = df[df['年龄'] > 20]
print(older_students)输出:
姓名 年龄 专业 入学年份
S02 李四 21 物理 2019
S03 王五 22 化学 2019处理烦人的缺失值
真实世界的数据总是不完美的,经常会有缺失值 (NaN)。
.isna(): 检测哪些地方是缺失值,返回一个布尔型的 DataFrame。.dropna(): 删除包含缺失值的行或列。.fillna(value): 将所有缺失值填充为指定的值value。
# 构造一个有缺失值的 DataFrame
data_missing = {'A': [1, 2, np.nan], 'B': [4, np.nan, 6]}
df_miss = pd.DataFrame(data_missing)
# 删除任何包含 NaN 的行
df_dropped = df_miss.dropna()
print(df_dropped)
# 将所有 NaN 填充为 0
df_filled = df_miss.fillna(0)
print(df_filled)修改你的数据
1. 添加新列
直接像给字典赋值一样。
# 根据已有列计算新列
df['毕业年份'] = df['入学年份'] + 4
print(df)2. 删除行或列
使用 .drop() 方法。
# 删除'入学年份'这一列
# axis=1 表示操作对象是列
df_dropped_col = df.drop('入学年份', axis=1)
# 删除'S01'这一行
# axis=0 表示操作对象是行 (默认)
df_dropped_row = df.drop('S01', axis=0)注意:.drop() 默认会返回一个新对象,而不是修改原始的 df。如果想直接修改,可以加上参数 inplace=True。
3.修改列名
如果你对现在的列名不满意,可以使用 rename 方法。
# 将 'A' 列改名为 'Alpha'
# inplace=True 表示直接修改原表格,而不是返回一个新的
df_miss.rename(columns={'A': 'Alpha'}, inplace=True)额外篇、Python 数据结构终极对比与总结
到目前为止,我们已经学习了Python中用于存储数据的各种“容器”,从基础的列表、元组,到用于科学计算的NumPy数组,再到为数据分析而生的Pandas Series和DataFrame。它们就像一个工匠的工具箱,每件工具都有其最擅长的领域。
在深入学习更高级的数据操作之前,让我们花点时间,把这些“神兵利器”放在一起,做一个全面的对比和总结。搞清楚它们的区别和适用场景,是让你从“会用”到“精通”的关键一步。
1. 各路“豪杰”简介
我们先用一句话快速回顾一下每个数据结构的“人设”:
- 列表 (List): 最基础、最灵活的数据抽屉,什么都能装,随时可以增删改查。
- 元组 (Tuple): 上了锁的保险箱,一旦存入数据就不能修改,安全可靠。
- 集合 (Set): 独一无二的收藏夹,自动去除重复项,擅长成员关系测试和数学运算。
- 字典 (Dictionary): 现实世界的字典,通过唯一的“键”(Key)快速查找对应的“值”(Value)。
- NumPy Array: 为数学而生的网格,所有元素类型统一,专为高性能、大规模的数值计算设计。
- Pandas Series: 带标签的超级一维数组,可以看作是NumPy数组的升级版,拥有更灵活的索引。
- Pandas DataFrame: 终极电子表格,一个带标签的二维数据表,是数据分析领域当之无愧的主角。
2. 核心特性对比表
为了更直观地展示它们的区别,我们整理了下面这张表格。这张表非常重要,建议你收藏起来时常回顾。
| 特性 | 列表 (List) | 元组 (Tuple) | 集合 (Set) | 字典 (Dictionary) | NumPy Array | Pandas Series | Pandas DataFrame |
|---|---|---|---|---|---|---|---|
| 结构 | 一维序列 | 一维序列 | 无序集合 | 键值对集合 | N维数组 | 带标签的一维数组 | 带标签的二维表格 |
| 可变性 | 可变 (Mutable) | 不可变 (Immutable) | 可变 (Mutable) | 可变 (Mutable) | 可变 (Mutable) | 可变 (Mutable) | 可变 (Mutable) |
| 有序性 | 有序 | 有序 | 无序 | 有序 (Python 3.7+) | 有序 | 有序 | 有序 |
| 元素唯一性 | 可重复 | 可重复 | 元素唯一 | 键(Key)唯一 | 可重复 | 可重复 | 可重复 |
| 元素类型 | 可混合不同类型 | 可混合不同类型 | 可混合不同类型 | 值(Value)可混合 | 必须为同一类型 | 通常为同一类型 | 每列通常为同一类型 |
| 索引方式 | 整数索引 | 整数索引 | 不支持索引 | 键(Key)索引 | 整数索引、切片、布尔 | 标签/整数索引、切片 | 行/列标签索引、切片 |
| 主要用途 | 通用数据存储 | 函数返回多个值、字典键 | 去重、成员测试、集合运算 | 存储映射关系 | 科学计算、数值运算 | 数据分析 (单列) | 数据分析、处理表格数据 |
| 性能 | 通用 | 通用 | 成员测试极快 | 键查找极快 | 数值运算极快 | 基于NumPy,运算快 | ���于NumPy,运算快 |
| 创建语法 | [1, 'a', 2] | (1, 'a', 2) | {1, 'a', 2} | {'a': 1, 'b': 2} | np.array([1, 2]) | pd.Series([1, 2]) | pd.DataFrame({'a':[1]}) |
3. 如何选择?一份决策指南
面对这么多选择,什么时候该用哪个呢?这里有一份简单的决策指南:
- 当你需要一个简单的、可以随时修改的列表时:
- 毫无疑问,使用 列表 (List)。它是最通用的选择。
- 当你需要存储一组不希望被改变的数据时(例如,函数返回的坐标点、配置信息):
- 使用 元组 (Tuple)。它的不可变性保证了数据的安全。
- 当你的核心需求是去除重复元素,或者判断一个元素是否在一个集合里时:
- 使用 集合 (Set)。它的去重和成员测试功能速度飞快。
- 当你需要存储一组有关联关系的数据,并通过一个唯一的标识来查找信息时(例如,存储学生信息,用学号作标识):
- 使用 字典 (Dictionary)。
- 当你需要进行大量的数学计算、矩阵运算、处理图像或声音等数值密集型任务时:
- 首选 NumPy Array。它是Python科学计算的基石。
- 当你处理的是一维带标签的数据,比如时间序列或者表格中的某一列时:
- 使用 Pandas Series。它提供了比NumPy更丰富的操作和对缺失数据的处理能力。
- 当你处理的是一个结构化的数据表,就像Excel或数据库中的表一样,需要进行筛选、分组、合并等复杂操作时:
- 使用 Pandas DataFrame。这是进行数据清洗、探索和分析的终极武器。
掌握了这些数据结构的选择之道,你处理数据的能力将大大提升。现在,让我们带着这些知识,继续深入探索Pandas更强大的功能。
十、Pandas 进阶:数据分组、重塑与合并
1. DataFrame 的常用操作回顾与进阶
在深入学习前,我们先快速回顾并补充一些日常非常有用的 DataFrame 操作。
查看、修改索引与筛选
df.rename(): 给列名或索引名换个名字。df.set_index('列名'): 将某一列设置为新的索引。df.reset_index(): 将索引重置为默认的 0, 1, 2…,原来的索引会变成新的一列(这在 Groupby 后非常有用)。- 数据筛选 (Filtering):这是数据分析最常用的功能。
- 单条件:
df[ df['Score'] > 60 ] - 多条件 :使用 & 和 | 连接,每个条件必须加括号。
import pandas as pd
data = {'Name': ['Mary', 'John', 'Jake'],
'Gender': ['Female', 'Male', 'Male'],
'Score': [88, 70, 55]}
df = pd.DataFrame(data)
# 筛选示例:找出分数不及格(<60) 的 男性(Male)
# 注意:两个条件都要用括号括起来,中间用 & 连接
failed_men = df[ (df['Gender'] == 'Male') & (df['Score'] < 60) ]
print("不及格的男性:")
print(failed_men)
排序与去重
df.sort_values(by='列名'): 根据指定列的值进行排序。df.drop_duplicates(): 删除重复的行。可以指定基于哪些列 (subset参数) 来判断是否重复。
data = {'学生': ['小明', '小红', '小明'], '分数': [88, 95, 88], '科目': ['数学', '数学', '数学']}
df = pd.DataFrame(data)
# 按分数降序排序
df_sorted = df.sort_values(by='分数', ascending=False)
print("排序后:")
print(df_sorted)
# 删除完全重复的行
df_unique = df.drop_duplicates()
print("\n去重后:")
print(df_unique)常用统计与转换
df.describe(): 快速查看数值型列的描述性统计信息(均值、标准差、最大/最小值等)。df['列名'].value_counts(): 统计某一列中每个值出现了多少次。df['列名'].unique(): 获取某一列中的所有不重复的值。
2. apply - 让操作更灵活
有时候,我们需要对数据的每一行或每一列执行一个自定义的复杂操作。这时 apply() 就派上用场了。
axis=0: 对每一列执行函数。axis=1: 对每一行执行函数。
data = {'语文': [85, 90, 78], '数学': [92, 88, 95]}
df = pd.DataFrame(data)
# 计算每门课的平均分(对列操作)
print(df.apply(lambda x: x.mean(), axis=0))
# 计算每个人的总分(对行操作)
df['总分'] = df.apply(lambda row: row['语文'] + row['数学'], axis=1)
print("\n计算总分后:")
print(df)我们经常需要根据现有的列生成新列(例如:根据 BMI 判断是否肥胖)。虽然 apply 可以做,但对于简单的 if-else 逻辑,使用 numpy.where 或直接布尔判断更简单高效。
import numpy as np
# 假设 df 中有 BMI 列
df = pd.DataFrame({'BMI': [22, 29, 31, 18]})
# 方法1:直接生成布尔值列 (True/False)
# 练习 4:如果 BMI >= 28 则为肥胖(Obesity)
df['Obesity'] = df['BMI'] >= 28
# 方法2:使用 np.where 生成分类列
# 语法:np.where(条件, 条件满足时的值, 不满足时的值)
df['Health_Status'] = np.where(df['BMI'] >= 28, 'Fat', 'Normal')
print("生成新列后:")
print(df)3. groupby - 数据分析的核心
groupby 是 Pandas 最强大的功能之一,它遵循“拆分-应用-合并”(Split-Apply-Combine)的逻辑。
- 拆分 (Split): 根据某个或某些列的数值,将数据拆分成不同的组。
- 应用 (Apply): 对每个组独立地执行一个函数(如求和、求平均值)。
- 合并 (Combine): 将计算结果合并成一个新的 DataFrame。
data = {'部门': ['销售部', '技术部', '销售部', '技术部', '行政部'],
'员工': ['张三', '李四', '王五', '赵六', '钱七'],
'工资': [8000, 12000, 8500, 15000, 6000]}
df = pd.DataFrame(data)
# 按部门分组
grouped = df.groupby('部门')
# 计算每个部门的平均工资
avg_salary = grouped['工资'].mean()
print("各部门平均工资:")
print(avg_salary)
# 对不同列执行不同操作
agg_result = grouped.agg({
'工资': 'mean', # 计算工资的平均值
'员工': 'count' # 计算部门人数
})
print("\n各部门统计信息:")
print(agg_result)4. 数据重塑:长宽格式转换
有时候数据的格式不方便我们分析,需要进行转换。
pivot(): 长格式变宽格式。将某一列的“值”变成新的“列名”。melt(): 宽格式变长格式。将多个“列名”变成某一列的“值”。
这两种操作互为逆运算,非常适合整理数据。
# 长格式数据
long_df = pd.DataFrame({
'城市': ['北京', '北京', '上海', '上海'],
'指标': ['GDP', '人口', 'GDP', '人口'],
'数值': [3.6, 2100, 3.8, 2400]
})
print("原始长格式数据:")
print(long_df)
# 使用 pivot 将长格式转为宽格式
wide_df = long_df.pivot(index='城市', columns='指标', values='数值')
print("\npivot 后的宽格式数据:")
print(wide_df)
# 使用 melt 将宽格式转回长格式
long_again = wide_df.reset_index().melt(id_vars='城市', var_name='指标', value_name='数值')
print("\nmelt 后的长格式数据:")
print(long_again)5. 数据合并
当数据分散在多个文件中时,我们需要将它们合并起来。
pd.concat() - 简单拼接
像搭积木一样,把多个 DataFrame 沿着一个轴(行或列)直接拼接起来。
axis=0: 垂直拼接(默认),行数增加。axis=1: 水平拼接,列数增加。
pd.merge() - 智能连接
merge 类似数据库中的 JOIN 操作,它根据一个或多个共同的列(键)来合并数据。
on: 指定用于连接的列名。how: 指定连接方式,最常用的有四种:'inner'(内连接): 只保留两个表中共同拥有的键。'left'(左连接): 保留左边表的所有行。'right'(右连接): 保留右边表的所有行。'outer'(外连接): 保留两个表的所有行。
df1 = pd.DataFrame({'学号': ['A01', 'A02', 'A03'], '姓名': ['张三', '李四', '王五']})
df2 = pd.DataFrame({'学号': ['A01', 'A02', 'A04'], '成绩': [95, 88, 92]})
# 内连接 (只有共同的学号 A01, A02)
inner_join = pd.merge(df1, df2, on='学号', how='inner')
print("内连接结果:")
print(inner_join)
# 左连接 (保留 df1 的所有学号)
left_join = pd.merge(df1, df2, on='学号', how='left')
print("\n左连接结果:")
print(left_join)十一、“类”与“对象”
你可能听说过“面向对象编程”,听起来很高级,但别担心,它的基础思想其实非常直观。学完本章,你将能够用一种全新的、更有条理的方式来组织你的代码。
1. 为什么需要“类”?一个生活中的例子
想象一下,你要盖房子。在动工之前,你肯定需要一张设计图。这张图纸上规定了房子有几间卧室、几个窗户、门在哪里等等。但图纸本身并不是房子,你不能住进去。
根据这张设计图,你可以建造出许多具体的房子。张三的房子、李四的房子……这些房子都遵循了图纸的设计,但每个房子又可以有自己独特的细节,比如墙壁颜色不同、家具不同。
在这个例子里:
- 设计图 → 就是 类 (Class)
- 具体的房子 → 就是 对象 (Object)
类 (Class) 是一个模板或蓝图,它定义了一类事物应该具有的共同特征(属性)和行为(方法)。
对象 (Object) 是根据这个模板创建出来的具体实例。
2. 创建你的第一个类
在 Python 中,创建一个类非常简单。我们来定义一个“小狗”的类。
class Dog:
# 这是“初始化方法”,也叫“构造方法”
# 当我们创建一个具体的 Dog 对象时,这个方法会自动运行
def __init__(self, name, age):
# self.name = name 的意思是:
# 把传入的 name 值,赋给这个具体对象自己的 name 属性
print(f"一只叫 {name} 的小狗诞生了!")
self.name = name
self.age = age
# --- 创建对象 ---
# 这就是“实例化”,根据 Dog 类的蓝图,创建两个具体的对象
dog1 = Dog("旺财", 2)
dog2 = Dog("小黑", 3)
# --- 访问对象的属性 ---
# 每个对象都有自己独立的属性
print(f"{dog1.name} 今年 {dog1.age} 岁了。") # 输出: 旺财 今年 2 岁了。
print(f"{dog2.name} 今年 {dog2.age} 岁了。") # 输出: 小黑 今年 3 岁了。这里有两个关键点:
__init__(self, ...):这是一个特殊的方法。名字前后的双下划线意味着它有特殊用途。它的作用就是在创建对象时,进行“初始化”设置,比如给对象的属性赋上初始值。self:这是类的方法中必须有的第一个参数。它代表对象实例本身。当你调用dog1 = Dog("旺财", 2)时,Python 会自动把dog1这个对象传递给self参数。所以self.name = name实际上就是dog1.name = "旺财"。你不需要手动传递它,但定义时必须写上。
3. 给对象添加行为——方法 (Method)
光有姓名、年龄这些属性还不够,狗还会有行为。在类里面定义的函数,我们就称之为方法 (Method)。方法不仅可以读取属性,还可以修改属性。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
# 定义一个方法:叫声
def bark(self):
# self 在这里同样代表调用这个方法的对象
print(f"{self.name} 正在汪汪叫!")
# 定义一个方法:过生日(修改属性)
def birthday(self):
print(f"祝 {self.name} 生日快乐!")
# 修改当前对象的 age 属性,加 1
self.age = self.age + 1
# 创建一个对象
my_dog = Dog("小白", 1)
# 调用方法
my_dog.bark() # 输出: 小白 正在汪汪叫!
print(my_dog.age) # 输出: 1
# 调用修改属性的方法
my_dog.birthday() # 输出: 祝 小白 生日快乐!
print(my_dog.age) # 输出: 2 (看,属性变了!)看到了吗?bark 和 birthday 方法通过 self 访问并操作了 my_dog 自己的属性。这就是方法与普通函数的最大区别:方法可以访问和操作对象自身的属性。
4. 两种属性:大家的和自己的
属性也分两种,一种是每个对象独有的,另一种是所有同类对象共享的。
- 实例变量 (Instance Variable):每个对象独有的属性,通常在
__init__中通过self.xxx定义。比如上面例子里的name和age。 - 类变量 (Class Variable):这个类的所有对象共享的属性。
我们给 Dog 类加一个“物种”属性,所有的狗都属于“犬科”,这个信息是共享的。
class Dog:
# 这是一个类变量,不属于任何一个实例,而是属于整个 Dog 类
species = "犬科"
def __init__(self, name, age):
# 这些是实例变量
self.name = name
self.age = age
dog1 = Dog("旺财", 2)
dog2 = Dog("小黑", 3)
# 可以通过类名直接访问
print(f"狗属于 {Dog.species}。") # 输出: 狗属于 犬科。
# 也可以通过实例访问
print(f"{dog1.name} 也属于 {dog1.species}。") # 输出: 旺财 也属于 犬科。5. 让对象“会说话”—— __str__ 方法
如果你直接 print 一个我们创建的对象,会得到一串奇怪的内存地址,很不友好。
my_dog = Dog("点点", 4)
print(my_dog) # 输出类似: <__main__.Dog object at 0x10e3b6a90>如果我们想让 print(my_dog) 输出更具可读性的信息,可以定义另一个特殊方法:__str__。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
# 定义当 print(对象) 时应该显示什么
def __str__(self):
return f"一只叫做 {self.name} 的狗,今年 {self.age} 岁了。"
my_dog = Dog("点点", 4)
print(my_dog) # 输出: 一只叫做 点点 的狗,今年 4 岁了。现在,输出结果就清晰多了!
6. 青出于蓝——继承 (Inheritance)
面向对象的一大魅力在于继承 (Inheritance)。它允许我们创建一个新类,这个新类可以“继承”一个已存在类的所有属性和方法,并可以添加自己独有的变量和方法。
比如,我们可以先定义一个更通用的 Animal 类,然后让 Dog 类和 Cat 类都继承它。
# 父类 (Parent Class)
class Animal:
def __init__(self, name):
self.name = name
def eat(self):
print(f"{self.name} 正在吃东西。")
# 子类 (Child Class)
# 括号里写上要继承的父类
class Dog(Animal):
# 子类可以定义自己的类变量
type = "哺乳动物"
def bark(self):
print(f"{self.name} 正在汪汪叫!")
class Cat(Animal):
def meow(self):
print(f"{self.name} 正在喵喵叫。")
# --- 测试一下 ---
my_dog = Dog("旺财")
my_cat = Cat("咪咪")
# 子类自动拥有了父类的方法
my_dog.eat() # 输出: 旺财 正在吃东西。
# 子类也可以调用自己独有的方法
my_dog.bark() # 输出: 旺财 正在汪汪叫!继承极大地提高了代码的复用性,让我们的代码结构更加清晰。
7. 三种方法:实例、类与静态方法
在 Python 类中,除了我们上面学到的普通方法(实例方法),还有两种特殊的方法,它们在处理一些特定任务时非常有用。
(1) 实例方法 (Instance Method)
这是最常见的,第一个参数必须是 self。它操作的是具体的对象。我们上面的 bark()、birthday() 都是这种。
(2) 类方法 (Class Method)
使用 @classmethod 装饰器。第一个参数必须是 cls (代表 Class 类本身),而不是 self。
它通常用于“工厂模式”,比如通过一种特殊的字符串格式来创建一个对象。
(3) 静态方法 (Static Method)
使用 @staticmethod 装饰器。它不需要 self 也不需要 cls 参数。
它就像一个普通的函数,只是正好放在了类里面,通常用来做一些辅助计算或工具功能。
让我们看一个“学生”的例子来理解它们的区别:
class Student:
def __init__(self, name, scores):
self.name = name
self.scores = scores # 这是一个分数列表
# --- 实例方法 ---
# 需要访问具体对象的 scores 属性
def get_average(self):
# 它可以调用下面的静态方法来帮忙计算
return Student.calculate_average(self.scores)
# --- 静态方法 ---
# 它不需要知道是哪个学生,只负责单纯的数学计算
# 就像一个独立的工具函数
@staticmethod
def calculate_average(score_list):
if len(score_list) == 0:
return 0
return sum(score_list) / len(score_list)
# --- 类方法 ---
# 它不需要现有的对象,而是用来“制造”新对象
# 场景:如果你拿到的数据是字符串 "Tom,90,80,70",想变成对象
@classmethod
def from_string(cls, student_str):
# 1. 解析字符串
parts = student_str.split(',')
name = parts[0]
# 把剩下的部分转成数字列表
scores = [int(x) for x in parts[1:]]
# 2. 调用类本身(cls)来创建对象,相当于 return Student(name, scores)
return cls(name, scores)
# 测试代码
# 1. 使用静态方法(像用工具一样)
avg = Student.calculate_average([80, 90, 100])
print(f"计算出来的平均分: {avg}")
# 2. 使用类方法(从字符串创建对象)
s1 = Student.from_string("Alice,85,95,90")
print(f"学生姓名: {s1.name}")
# 3. 使用实例方法(获取该学生的平均分)
print(f"{s1.name} 的平均分: {s1.get_average()}")十二、 Matplotlib 核心用法
在 Python 的世界里,当我们想把枯燥的数据变成直观的图表时,第一个想到的库通常就是 Matplotlib。
核心思想:像画画一样思考
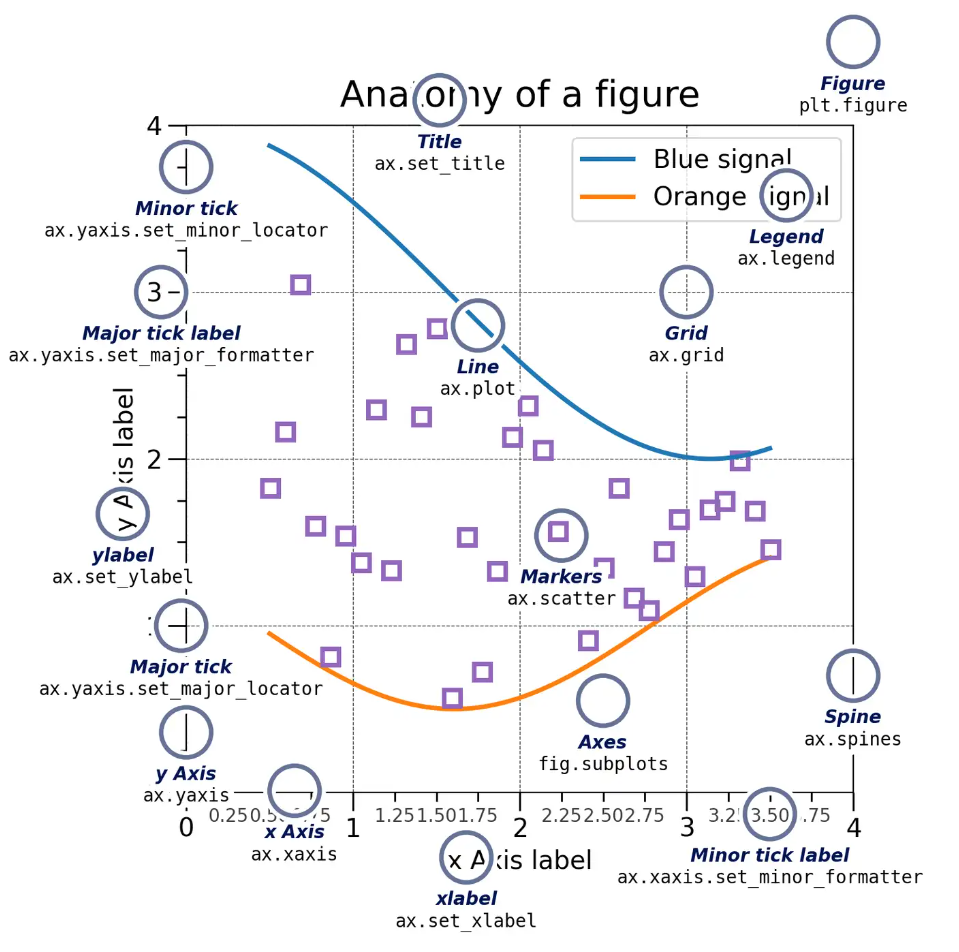
在使用 Matplotlib 时,不要把它想得太复杂。我们可以把它想象成一个画画的过程,只需要记住两个核心概念:
- Figure (画布):这是整个图表的“画布”,是所有内容的载体。你可以把它想象成你买来的一张空白画纸。
- Axes (坐标系/子图):这是画布上的“画板”或“绘图区”。我们所有的绘图操作,比如画线、画点,都是在这个区域里完成的。一张画布上可以只有一个画板,也可以有多个。
我们推荐使用一种被称为面向对象 (Object-Oriented) 的绘图方式。简单来说,就是先准备好“画布” (Figure) 和“画板” (Axes),然后明确地告诉程序要在哪个“画板”上画画。这样做的好处是逻辑清晰,尤其是在处理复杂图表或多张子图时,不容易出错。
准备工作:搭好你的画架
在开始画画前,我们需要准备好工具。
首先,导入必要的库。matplotlib.pyplot 是我们的画笔,通常简写为 plt。由于数据处理经常和 NumPy 一起使用,我们也会一并导入它。
import matplotlib.pyplot as plt
import numpy as np在 Jupyter Notebook 中,加上这行可以让图表直接显示

接下来,我们用最推荐、最常用的一行代码来创建画布和坐标系:
# 创建一个 Figure 和一个 Axes
fig, ax = plt.subplots() 这行代码 plt.subplots() 会返回两个东西:fig (我们的画布) 和 ax (我们的坐标系)。现在,我们就可以在 ax 这个画板上大展拳脚了。
开始作画:绘制你的第一张图
我们先从最简单的线图 (plot) 开始。假设我们有一组 x 和 y 的数据。
# 准备数据
x = np.linspace(0, 10, 100) # 从0到10生成100个点
y = np.sin(x)
# 在 ax 上绘制线图
ax.plot(x, y)
# 为了看到最终效果,可以加上这句(在脚本中运行时必需)
# plt.show() 运行后,你就能看到一条平滑的正弦曲线。ax.plot() 是最基础的绘图命令,它接收 x 和 y 坐标数据,然后将它们连接成线。
精雕细琢:美化你的图表
一张光秃秃的图表是没有灵魂的。我们需要给它加上标题、标签,甚至修改线条的样式(比如虚线、圆点)。这些操作都是在 ax 对象上完成的。
让我们把上面的例子变得更完善:
# 1. 重新创建画布和坐标系
fig, ax = plt.subplots(figsize=(8, 5)) # figsize可以设置画布大小
# 2. 绘制数据,并为线条添加 label,用于图例显示
ax.plot(x, y, label='正弦曲线', color='r', linestyle='--') # 设置颜色和线条样式
# 3. 添加标题和坐标轴标签
ax.set_title("一个简单的正弦函数图像", fontsize=16)
ax.set_xlabel("X 轴", fontsize=12)
ax.set_ylabel("Y 轴", fontsize=12)
# 4. 设置坐标轴范围
ax.set_xlim(0, 10)
ax.set_ylim(-1.2, 1.2)
# 5. 显示网格线
ax.grid(True)
# 6. 显示图例
ax.legend()
# plt.show()
通过调用 ax.set_title(), ax.set_xlabel(), ax.set_ylabel() 等一系列 set_* 方法,我们可以像搭积木一样,一步步地完善图表的每一个细节。
更多画风:探索其他常用图表
除了线图,Matplotlib 还支持多种图表类型。我们来看几个最常见的:
1. 散点图 (Scatter Plot)
散点图用于展示两个变量之间的关系。
# 准备数据
x_scatter = np.random.rand(50) * 10
y_scatter = np.random.rand(50) * 10
# 创建图表
fig, ax = plt.subplots()
ax.scatter(x_scatter, y_scatter, c='blue', marker='o') # c是颜色, marker是点的形状
ax.set_title("散点图示例")
# plt.show()2. 条形图 (Bar Chart)
条形图常用于比较不同类别的数据。在科研或实验数据中,我们经常需要加上“误差棒” (Error Bar) 来表示数据的波动范围。
# 准备数据
categories = ['Plant A', 'Plant B', 'Plant C']
values = [10, 9, 5] # 柱子的高度
errors = [0.5, 0.4, 1] # 误差范围(标准差等)
# 创建图表
fig, ax = plt.subplots()
# yerr 参数用于画误差线,capsize 设置误差线上下两头横线的宽度
ax.bar(categories, values, color='green', yerr=errors, capsize=5)
ax.set_title("带误差棒的植物高度")
ax.set_ylabel("高度 (cm)")
# plt.show()3. 直方图 (Histogram)
直方图用于展示数据的分布情况。
# 准备数据 (生成1000个符合正态分布的随机数)
data = np.random.randn(1000)
# 创建图表
fig, ax = plt.subplots()
ax.hist(data, bins=30, edgecolor='black') # bins指定了要分的区间数量
ax.set_title("直方图示例")
ax.set_xlabel("数值")
ax.set_ylabel("频率")
# plt.show()4. 饼图 (Pie Chart)
饼图用于展示各部分占整体的比例,比如编程语言的流行度。
labels = ['Python', 'C++', 'Java', 'Go']
sizes = [45, 30, 15, 10] # 各部分数值
explode = (0.1, 0, 0, 0) # "炸开"第一块(Python),突出显示
fig, ax = plt.subplots()
# autopct='%1.1f%%' 用于显示百分比,保留一位小数
ax.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax.axis('equal') # 保证饼图画出来是圆的,不是椭圆
组合画作:在同一画布上绘制多图
有时候,我们需要将多张图表放在一起进行对比。plt.subplots() 可以轻松实现这一点。只需要在调用时传入行数和列数即可。
# 创建一个 1 行 2 列的子图布局
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
# 在第一个子图 (axes[0]) 上画线图
axes[0].plot(x, y, 'r-')
axes[0].set_title('线图')
# 在第二个子图 (axes[1]) 上画散点图
axes[1].scatter(x_scatter, y_scatter, c='b')
axes[1].set_title('散点图')
# 自动调整子图间距,防止重叠
fig.tight_layout()
# plt.show()plt.subplots(1, 2) 会返回一个包含两个 Axes 对象的数组 axes,我们可以通过索引 axes[0] 和 axes[1] 来分别操作它们。
复杂布局 (GridSpec)
有时候 plt.subplots 创建的规则网格(比如2行2列)满足不了需求。比如你想左边放一张大图,右边放两张小图。这时就需要 GridSpec。
# 创建一个 2行 2列 的网格规划
fig = plt.figure(figsize=(10, 6))
gs = fig.add_gridspec(2, 2)
# 添加子图:利用切片语法
# ax1 占据所有行的第0列(即左边整列)
ax1 = fig.add_subplot(gs[:, 0])
ax1.set_title("我是左边的大图")
ax1.plot([1, 2, 3], [1, 2, 3])
# ax2 占据第0行的第1列(即右上)
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title("我是右上")
# ax3 占据第1行的第1列(即右下)
ax3 = fig.add_subplot(gs[1, 1])
ax3.set_title("我是右下")
plt.tight_layout()
保存你的杰作
当你对图表满意后,可以用 fig.savefig() 将它保存为图片文件。
# 假设我们已经画好了一张图,画布对象是 fig
# ... 绘图代码 ...
# 保存图片
fig.savefig("my_beautiful_plot.png", dpi=300, bbox_inches='tight')- 文件名
my_beautiful_plot.png的后缀决定了保存的格式(如.png,.jpg,.pdf)。 dpi=300设置了图片的分辨率,数值越高越清晰。bbox_inches='tight'是一个非常有用的参数,它可以自动裁剪掉图片周围多余的白边。
十三、 Python 数据可视化
在大学的 Python 数据分析课程中,我们其实主要就在和三个库打交道:Pandas(管数据的)、Matplotlib(画基础图的)和 Seaborn(画统计图的)。
很多同学觉得代码难记,其实是因为没理清它们各自的角色。今天我们就用最平淡的大白话,把这章的核心知识点串一串。
1. Pandas:数据的“Excel”
在 Python 里,Pandas 就是一个超级强大的 Excel。我们在代码里用它,主要就做三件事:读取、清洗、分组。
读取数据
首先要把电脑里的 CSV 文件读进 Python,变成一个叫 DataFrame(数据框)的东西。你可以把它想象成把 Excel 表格加载到了内存里。
import pandas as pd
# parse_dates 是个很实用的参数
# 它告诉 Python:“dateRep 这一列是日期,别当成普通文本读进来”
# 这样后面我们才能按“月”或“年”来筛选
df = pd.read_csv('data.csv', parse_dates=['dateRep'])筛选数据
数据读进来往往太多,我们需要挑出我们关心的部分。比如只看美国和英国的数据:
# isin 就是“在...里面”的意思
# 逻辑:去 geoId 这一列看看,如果值是 'US' 或 'UK',就把这一行留下
filtered_df = df[df['geoId'].isin(['US', 'UK'])]分组统计 (Pivot Table)
这是数据分析最核心的功能。原始数据往往是“每天”的流水账,但作业通常要求画“每月”的走势图。这就需要 groupby。
# 逻辑:先按‘国家’分堆,再在每个国家里按‘年月’分堆
# .sum():分好堆后,把病例数加起来
monthly_data = df.groupby(['geoId', 'year_month']).sum()2. Matplotlib:画图的“地基”
Matplotlib 是 Python 最基础的画图库。说实话,它代码写起来有点繁琐,但它的优势在于能控制图表的每一个细节(比如坐标轴刻度、画布大小)。
铺开画布
画画之前,先得决定纸有多大。
import matplotlib.pyplot as plt
# figsize=(12, 6) 就是宽 12 英寸,高 6 英寸
plt.figure(figsize=(12, 6))画折线图
最常用的绘图命令。
# label:给这条线起个名,后面做图例(Legend)要用
# linestyle:'--' 是虚线,'-' 是实线
plt.plot(x, y, label='US Cases', linestyle='--')
plt.legend() # 显示图例搞个“拼图” (Subplots)
有时候你想在一张大图里放 4 张小图,这就需要用到 subplots。
# 把画布切成 2 行 2 列,一共 4 个格子
fig, axes = plt.subplots(2, 2)
# 告诉 Python:第一张图画在左上角 (0,0)
axes[0, 0].plot(x, y)
# 第二张画在右上角 (0,1)...
axes[0, 1].plot(x, z)3. Seaborn:画图的“美颜相机”
Seaborn 是建立在 Matplotlib 之上的。它更智能,默认样式更好看,而且特别擅长处理统计数据。
hue 参数 (最重要!)
这是 Seaborn 最强大的功能——自动上色。
以前用 Matplotlib,你得写循环:“如果是 A 类给红色,如果是 B 类给蓝色”。在 Seaborn 里,你只要告诉它 hue="species"(hue 是色调的意思):
import seaborn as sns
# 它会自动看“species”这一列有几种企鹅,自动分配颜色,自动画图例
sns.scatterplot(data=df, x="bill_length", y="bill_depth", hue="species")常见统计图表
Seaborn 封装了很多高级图表,专门用来展示数据的分布:
- sns.boxplot (箱线图):用来由看数据的范围和异常值。中间那条线是中位数,箱子外面的点是“离群点”(比如一只特别胖的企鹅)。
- sns.violinplot (小提琴图):箱线图的升级版。胖胖的地方表示那里数据比较多,瘦的地方表示数据少。
- sns.heatmap / clustermap (热图):用颜色深浅来表示数值大小。
clustermap还会自动把相似的数据聚在一起(聚类),让你一眼看出哪些样本是相似的。
KDE (核密度估计)
听起来很数学,其实就是平滑的直方图。
直方图是一根根柱子,kind="kde" 就是把柱子顶端连成一条平滑的曲线,让你看清楚数据的分布形状(是山峰状,还是平顶状)。
4. 两个必考的 Python 语法点
除了上面三个库,处理数据时还有两个“咒语”经常用到。
删除空值的高级写法
如何删除表格里含有空值的行?
# df.isna():检查哪些格子是空的
# .any(axis=1):只要这一行里有一个格子是空的,就标记为 True
# ~:取反。我们要留下的,是那些“没有”空值的行
clean_df = df[~df.isna().any(axis=1)]dt 访问器
当一列数据是时间格式时,你不能直接操作。必须加上 .dt (date/time 的缩写) 才能使用时间专属的功能。
# 把日期转换成“月”的格式(例如 2023-01)
df['year_month'] = df['dateRep'].dt.to_period('M')十四、统计学与聚类分析
这一章我们跳出单纯的编程语法,进入数据分析的核心领域。我们将利用 Python 中最强大的几个库:Pandas, Numpy, Scipy 和 Scikit-learn,来处理描述性统计、假设检验以及机器学习基础。
一、 描述性统计 (Descriptive Statistics)
描述性统计的作用是总结数据集的特征。主要关注两点:数据集中在哪里(集中趋势),以及数据分散得有多开(离散程度)。
1. 集中趋势 (Central Tendency)
我们常用三个指标来描述数据的“中心”:
- Mean (均值): 所有数据的平均值。
- Median (中位数): 排序后位于中间的数值。
- 关键点: 如果数据中存在极端的 Outliers (异常值),Mean 会被拉偏,此时 Median 是更好的选择。
- Mode (众数): 出现次数最多的数值。
代码示例:
import pandas as pd
import numpy as np
data = {'score': [85, 90, 88, 92, 1000]} # 1000 是一个异常值
df = pd.DataFrame(data)
# 计算均值
print("Mean:", df['score'].mean()) # 结果会被 1000 拉高
print("Mean (Numpy):", np.mean(df['score']))
# 计算中位数
print("Median:", df['score'].median()) # 结果更接近真实水平
print("Median (Numpy):", np.median(df['score']))
# 计算众数
print("Mode:", df['score'].mode())2. 离散程度 (Measures of Dispersion)
描述数据波动的大小:
- Range (极差):
Max - Min。非常容易受异常值影响。 - IQR (四分位距): 第75百分位数 (Q3) 减去第25百分位数 (Q1)。它比 Range 更稳定,常用于过滤异常值。
- Standard Deviation (标准差): 数据偏离均值的程度。
- Variance (方差): 标准差的平方。
代码示例:
from scipy import stats
# 极差
data_range = df['score'].max() - df['score'].min()
# 四分位距 (IQR)
q3, q1 = np.percentile(df['score'], [75, 25])
iqr_val = q3 - q1
# 或者使用 scipy
iqr_scipy = stats.iqr(df['score'])
# 标准差与方差
std_val = df['score'].std() # Pandas 默认计算样本标准差
var_val = df['score'].var()二、 推断性统计 (Inferential Statistics)
推断性统计通过分析样本数据,来推测总体数据的特征。这里主要涉及假设检验。
1. 假设检验 (Hypothesis Tests)
- T-test (T检验): 用于比较两组数据的均值是否有显著差异。前提是数据通常需要服从正态分布。
- Independent T-test: 比较两组独立样本(例如:男生组 vs 女生组)。
- Paired T-test: 比较两组相关样本(例如:同一群人吃药前 vs 吃药后)。
- 非参数检验 (Non-parametric tests): 当数据不服从正态分布时使用。
- Mann-Whitney U Test: 对应独立样本 T 检验的非参数版本。
- Kolmogorov-Smirnov Test: 检验两个样本是否来自同一分布。
代码示例:
from scipy import stats
group_a = [80, 85, 88, 90, 95]
group_b = [70, 75, 78, 80, 85]
# 独立样本 T检验
t_stat, p_val = stats.ttest_ind(group_a, group_b)
print(f"P-value: {p_val}") # 如果 p < 0.05,通常认为差异显著
# 配对 T检验 (假设 a 和 b 是同一组人的两次测试)
t_stat_rel, p_val_rel = stats.ttest_rel(group_a, group_b)
# Mann-Whitney U 检验 (数据分布未知时)
u_stat, p_val_mw = stats.mannwhitneyu(group_a, group_b)三、 Scikit-learn 机器学习基础
原有的统计部分主要用于分析数据,而在解决实际预测问题时,我们需要使用 scikit-learn 库建立标准的工作流程。在进行机器学习任务(回归、分类、聚类)时,通常遵循以下三个核心步骤:
1. 数据集分割 (Train-Test Split)
为了验证模型是否真的学会了规律,而不是死记硬背,我们必须把数据分为两部分:
- 训练集 (Training set): 比如 80% 的数据,用来教模型。
- 测试集 (Test set): 剩下的 20% 数据,用来考试。
from sklearn.model_selection import train_test_split
# X 是特征(题目),y 是目标(答案)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)2. 数据标准化 (Standardization)
很多算法(如 PCA, KMeans, 逻辑回归)对数据的尺度非常敏感。如果一个特征是“米”(0-2),另一个是“毫米”(0-2000),模型会误以为后者更重要。
我们需要使用 StandardScaler 将所有特征缩放到同一量级(均值为0,方差为1)。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 在训练集上学习均值并转换
X_test_scaled = scaler.transform(X_test) # 用同样的标准转换测试集3. 监督学习:回归与分类
- 回归 (Regression): 预测一个连续的数值(例如:预测房价)。
- 使用
LinearRegression。 - 评估指标:MSE (均方误差),越小越好。
- 使用
- 分类 (Classification): 预测一个类别(例如:预测是否患癌)。
- 使用
LogisticRegression(逻辑回归)。虽然名字带“回归”,但它是用来分类的。 - 评估指标:Accuracy (准确率)。
- 使用
代码示例:
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.metrics import mean_squared_error
# --- 回归任务 ---
reg = LinearRegression()
reg.fit(X_train_scaled, y_train) # 训练
y_pred = reg.predict(X_test_scaled) # 预测
mse = mean_squared_error(y_test, y_pred) # 评估
print("MSE:", mse)
# --- 分类任务 ---
clf = LogisticRegression()
clf.fit(X_train_scaled, y_train)
acc = clf.score(X_test_scaled, y_test) # 直接计算准确率
print("Accuracy:", acc)四、 聚类 (Clustering)
聚类是一种无监督学习,目的是把相似的对象归为一类(Practice 3)。
1. K-Means 算法
这是最经典的聚类算法。原理是随机选 K 个中心点,不断调整直到稳定。
2. 评估:轮廓系数 (Silhouette Score)
在没有标准答案(无监督)的情况下,我们怎么知道聚类好不好?
- 使用 Silhouette Score。
- 范围是 -1 到 1。数值越接近 1,说明分得越好(同类距离近,异类距离远)。
代码示例:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import numpy as np
X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]])
# 1. 训练模型
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans.fit(X)
# 2. 获取标签
labels = kmeans.labels_
# 3. 评估效果
score = silhouette_score(X, labels)
print(f"Silhouette Score: {score}")五、 主成分分析 (PCA)
PCA (Principal Component Analysis) 是一种降维技术。
- 目的: 把高维复杂数据(比如30个特征)压缩到低维(比如2个特征),方便画图或计算。
- 关键: 降维前必须进行标准化。
代码示例 (Practice 4 核心):
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 假设 X 有 4 个特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 1. 先标准化
pca = PCA(n_components=2) # 2. 指定降到 2 维
X_pca = pca.fit_transform(X_scaled)
print(X.shape) # (150, 4)
print(X_pca.shape) # (150, 2) -> 现在可以画在二维平面上了
Comments