从五级流水线到 VLIW:ARMv3 处理器微架构设计与 FPGA 验证

在微处理器设计课程中,我们四人团队从零构建了一颗完整的 ARMv3 架构处理器——从五级流水线、Cache 子系统到浮点单元,并最终扩展至 VLIW 双发射架构,全部在 Nexys A7 FPGA 上完成板级验证。
一、项目全景:不止是"写一个CPU"
这不是一个简单的单周期 CPU 课程实验。整个项目分八个递进模块,覆盖了现代处理器设计的核心技术栈:
- Q1 · 五级流水线 + 冒险处理:将单周期 ARMv3 拆分为 IF→ID→EX→MEM→WB 五级流水,实现 Forwarding、Stalling 解决数据/控制冒险
- Q2 · 多周期指令无阻塞执行:扩展 MUL/DIV 等长延迟指令的数据依赖检测与流水线互锁
- Q3 · 全16条数据处理指令:ALU 硬件复用设计,在少量逻辑资源下支持 ADD/SUB/AND/ORR/MOV/MVN 等全部 ARM 数据处理指令
- Q4 · 4-Way 组相联 Cache:4KB Cache,Write-Allocate + Write-Back 策略,LRU 替换算法 —— 本人的主要工作
- Q5 · IEEE 754 浮点单元:完整 FPU 支持浮点加减乘除,处理 NaN/无穷大等边界情况
- Q6 · 单周期 RISC-V 处理器:对比 ARM 架构差异,实现 RV32I 指令集
- Q7 · RISC-V 五级流水线:将 RISC-V 版本流水线化,完成冒险处理
- Bonus · VLIW 双发射架构:静态调度的超长指令字架构,单周期并行执行两条指令 —— 本人的主要工作
二、Cache 子系统:4-Way 组相联 + LRU 替换
现代处理器的性能瓶颈不在 CPU 核,而在存储墙。Cache 设计的优劣直接决定系统吞吐量。我们实现了 4KB 四路组相联 Cache,组织为 256 行 × 4 路 × 4 字节,采用 Write-Allocate(写缺失时先加载块再写入)和 Write-Back(脏块仅在被替换时写回内存)策略。

地址划分与命中判定
32 位地址划分为 Tag(22 bit)、Index(8 bit)、Offset(2 bit)。每一路独立维护 Valid Bit、Dirty Bit 和 22-bit Tag:
wire [21:0] RWAddr_tag = RWAddr[31:10]; // Tag: 高22位
wire [7:0] RWAddr_index = RWAddr[9:2]; // Index: 选择256行中的一行
// Offset [1:0]: 块内字节偏移(4字节/块)
assign Hit = Tag0Equal | Tag1Equal | Tag2Equal | Tag3Equal;LRU 替换算法
每次 Cache 访问后更新该行四路的 LRU 优先级标记。当需要替换时,选择 LRU 值最大(最久未用)的路进行淘汰。设计中特别解决了LRU 计数器溢出导致的排序错误——通过限制 LRU 增量为 1 且仅在命中时重置为 0,保证了无限次命中后排序仍然正确。
// LRU 更新策略:命中路重置为 0,其他路中比它小的全部 +1
always @(posedge CLK) begin
if (Usecache) begin
for (j = 0; j < 4; j = j + 1) begin
if (j == B_NUM)
LRU[RWAddrIndex][j] <= 2'd0; // 命中的路优先级最高
else if (LRU[RWAddrIndex][j] < LRU[RWAddrIndex][B_NUM])
LRU[RWAddrIndex][j] <= LRU[RWAddrIndex][j] + 1;
end
end
end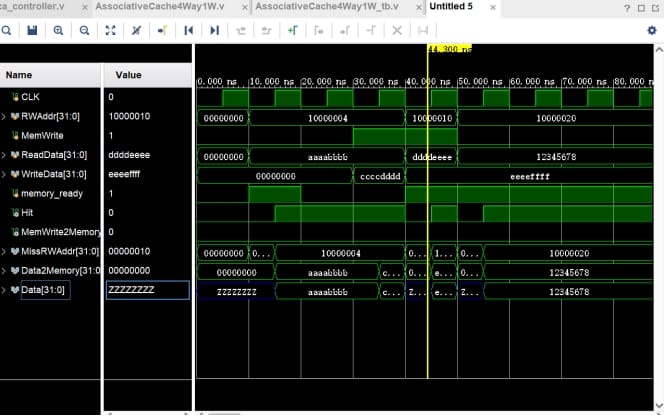
三、VLIW:让处理器"一心二用"
超标量处理器靠硬件动态调度实现指令级并行——这需要复杂的乱序执行逻辑和大量的硅面积。VLIW(超长指令字)走了另一条路:把调度的责任交给编译器,硬件只需要一个最简单的双发射控制器。
设计中,我们将两个独立的 ARM Core 实例化在 VLIW 模块内,通过 PC 交错分配指令——ARM0 执行偶数行、ARM1 执行奇数行——实现每周期同时发射两条无依赖关系的指令。
// VLIW 双核实例化
ARM arm0(.CLK(CLK), .Reset(RESET), .Instr(Instr0), ...); // 偶数行指令
ARM arm1(.CLK(CLK), .Reset(RESET), .Instr(Instr1), ...); // 奇数行指令
// PC 交错分配
assign OUT_PC0 = PC0 + PC0; // ARM0: 0, 2, 4, 6...
assign OUT_PC1 = PC1 + PC1 + 4; // ARM1: 1, 3, 5, 7...测试代码同时发射 ADD/SUB/AND 指令对,使用两组独立的寄存器(R0-R7 和 R8-R15)避免数据依赖:
; 双发射指令对 1 —— 同时执行
ADD R0, R0, R1 ; 奇数行 → ARM0 执行
ADD R8, R8, R9 ; 偶数行 → ARM1 执行
; 双发射指令对 2
SUB R2, R2, R3
SUB R10, R10, R11
; 双发射指令对 3
AND R4, R4, R5
AND R12, R12, R13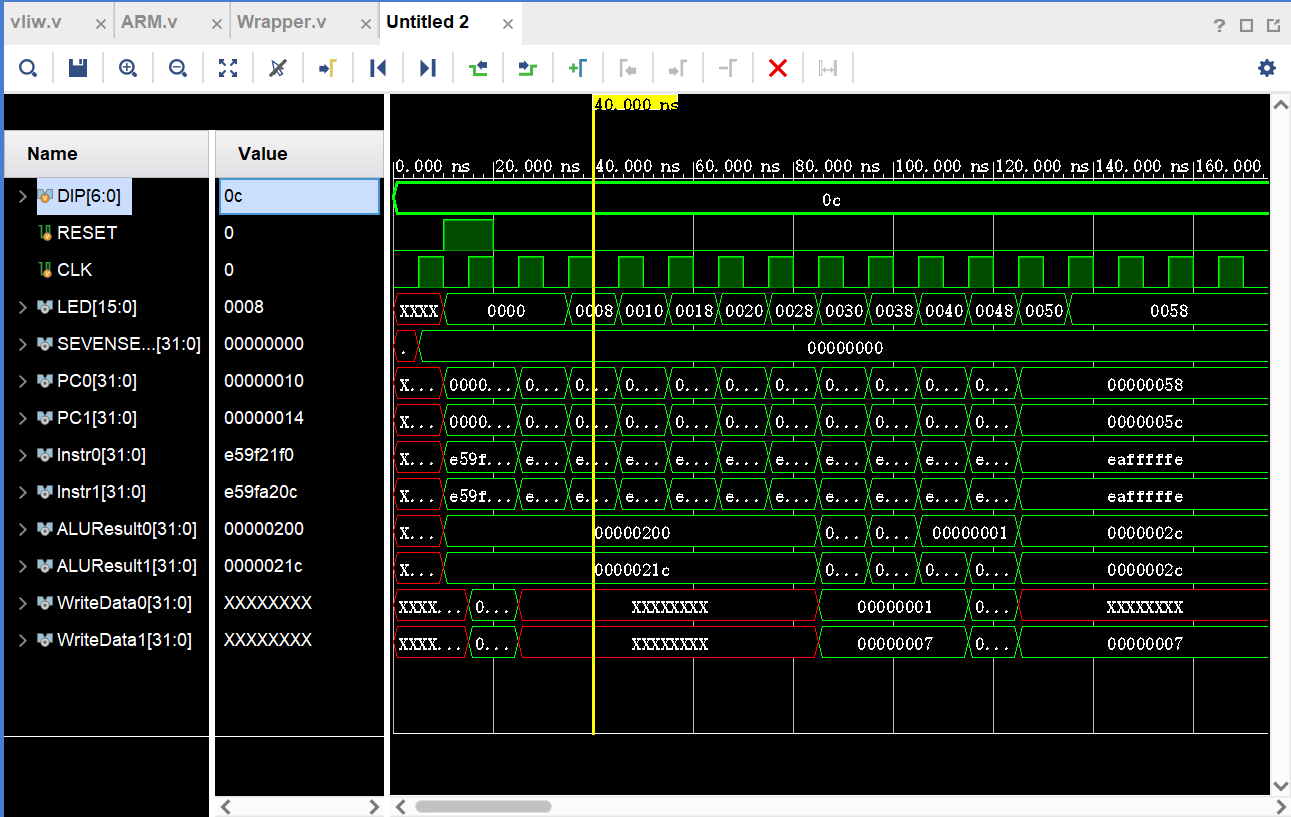
测试结果:16 条指令在 仅 8 个周期内完成,相比单发射处理器效率翻倍。验证了 VLIW 架构在编译器充分调度下可以实现近乎线性的加速比。
四、从仿真到真实硬件
所有模块均经历了完整的 Verilog 仿真 → 综合 → 布局布线 → 烧录验证流程。在 Nexys A7(Xilinx Artix-7 100T)FPGA 上完成了 ARMv3 五级流水线、Cache、FPU 和 RISC-V 处理器的板级实测——拨码开关输入指令、LED 数码管显示结果、VGA 输出波形。
这不仅是一次课程作业,更是对处理器微架构设计全流程的完整实践:从指令集理解、流水线冒险分析、存储层次设计到指令级并行探索——每一步都在回答"计算机是如何工作的"这个根本问题。
Comments