Dog Breed Classification: Transfer Learning with ResNet152 + Inception v3 + Xception Three-Model Ensemble
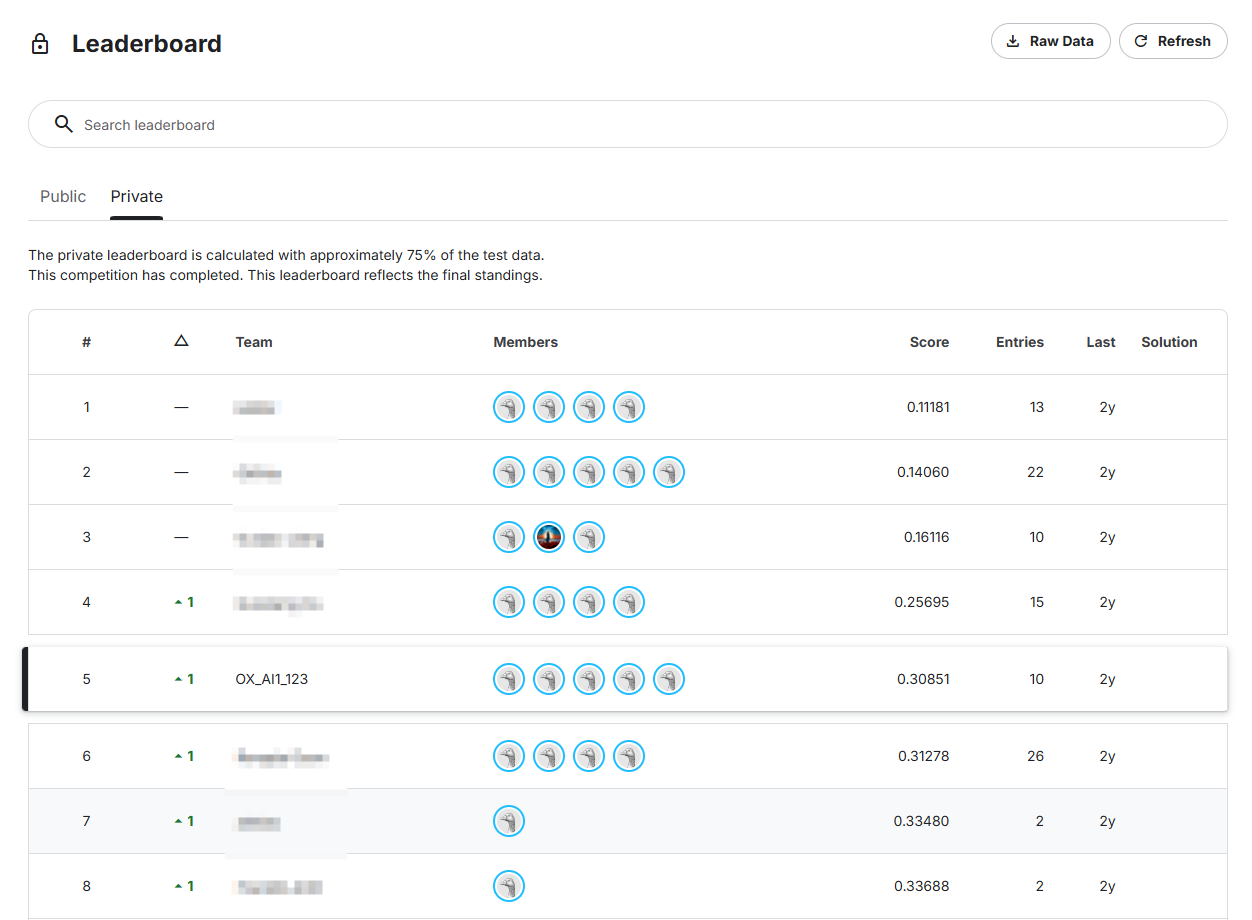
In the Oxford University machine learning course, we participated in the Kaggle dog breed classification competition—given a photo of a dog, the model must correctly identify its breed from 120 categories. We adopted a three-model ensemble (ResNet152 + Inception v3 + Xception) transfer learning approach, ultimately achieving 91% classification accuracy on the test set and a Kaggle score of 0.30508.
The data distribution is as follows:
1. The Iterative Path from Single Model to Three-Model Ensemble
What is most worth summarizing about this project is not the final solution itself, but the process of progressively approaching the optimal solution through four iterative rounds:
Round 1: Starting with a Single Model (Failure)
Directly used pre-trained ResNet50 / EfficientNet-B0, replacing the final fully connected layer and starting training. The result showed validation set accuracy far lower than training set accuracy—classic overfitting. A single model's 2048-dimensional feature vector was insufficient to cover the fine-grained differences across 120 breeds.
Round 2: Freezing Parameters + Data Augmentation (Partial Improvement)
Froze ResNet50 convolutional layer weights, trained only the final FC layer, combined with RandomCrop, ColorJitter, and HorizontalFlip data augmentation. Overfitting was somewhat alleviated, but classification on complex images remained unstable.
Round 3: Dual-Model Feature Fusion (Continuous Progress)
Introduced Inception v3 and ResNet152 to extract features in parallel, concatenating the two models' 2048-dimensional feature vectors into 4096 dimensions. Multi-scale features (Inception) complemented deep features (ResNet), markedly improving accuracy, though training time doubled and some redundant features led to new overfitting.
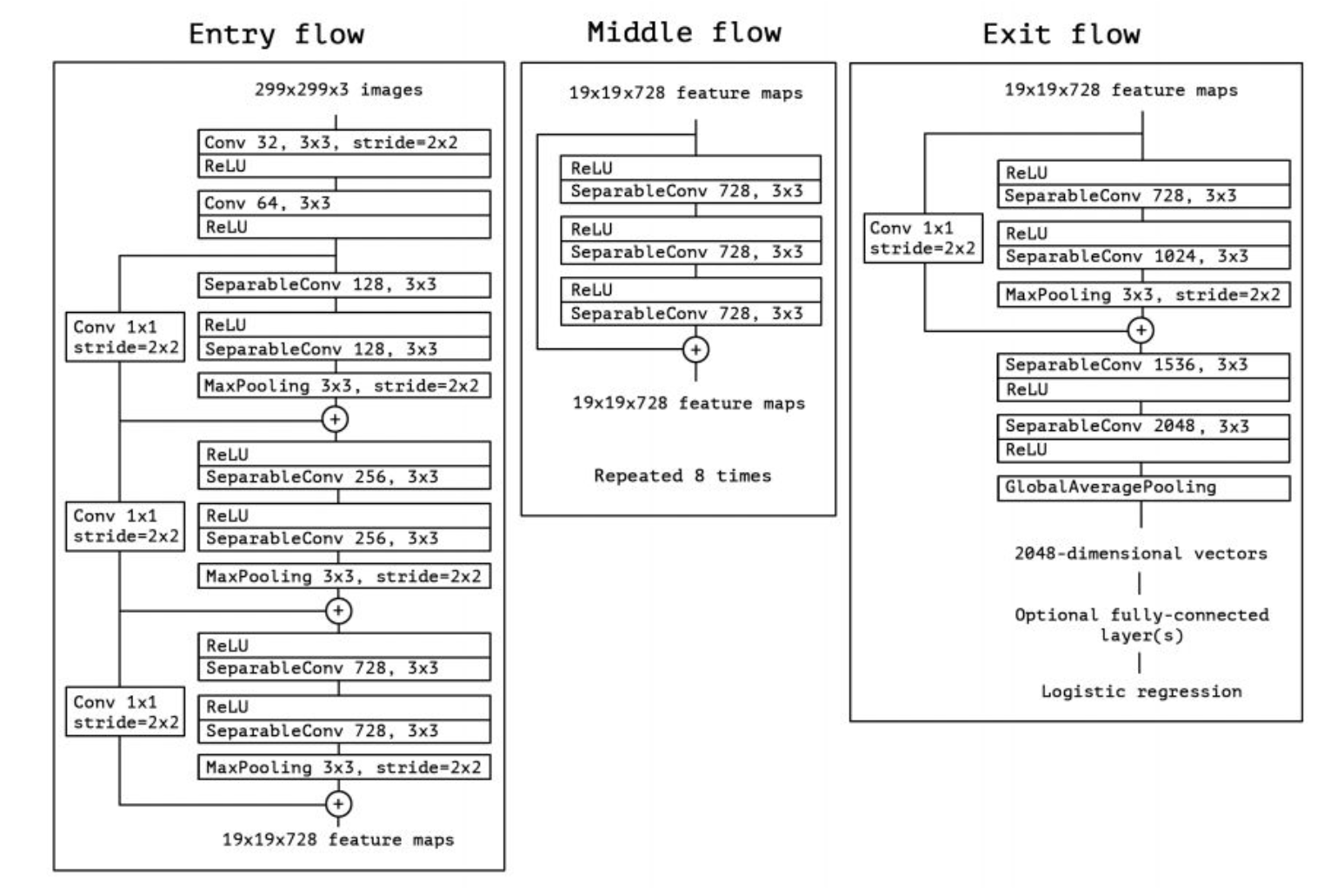
Round 4: Three-Model Ensemble + Dynamic Learning Rate (Best)
Final solution: ResNet152 + Inception v3 + Xception three models in parallel, each with frozen pre-trained weights, concatenating 6144-dimensional feature vectors fed into the final fully connected layer:
class CombinedResNetInception(nn.Module):\n def __init__(self, n_class):\n # Load three pre-trained models\n self.resnet = models.resnet152(pretrained=True)\n self.inception = models.inception_v3(pretrained=True)\n self.xception = timm.create_model('xception', pretrained=True)\n\n # Freeze all convolutional layer weights\n for param in self.resnet.parameters(): param.requires_grad = False\n for param in self.inception.parameters(): param.requires_grad = False\n for param in self.xception.parameters(): param.requires_grad = False\n\n # Remove classification heads, retain feature extractors\n self.inception.fc = nn.Identity()\n self.xception.fc = nn.Identity()\n self.resnet.fc = nn.Identity()\n\n # Concatenate 2048×3 = 6144 dims → 120 classes\n self.fc = nn.Linear(2048 + 2048 + 2048, n_class)\n\n def forward(self, x):\n x_resnet = self.resnet(x)\n x_inception = self.inception(x)\n x_xception = self.xception(x)\n x = torch.cat((x_resnet, x_inception, x_xception), dim=1)\n return self.fc(x)Combined with Adam optimizer (lr=0.0001) + ReduceLROnPlateau (patience=2, factor=0.5) for dynamic learning rate adjustment, training automatically stops early when validation set accuracy stops improving.
2. Training Strategy
- Transfer Learning: All three models pre-trained on ImageNet, feature extraction layers frozen, only the final FC classification head trained
- Data Augmentation: RandomResizedCrop(299) + RandomHorizontalFlip + Normalize — Inception/Xception fixed input 299×299
- Loss Function: CrossEntropyLoss
- Learning Rate Scheduling: ReduceLROnPlateau halves learning rate when validation accuracy fails to improve for 2 consecutive epochs
- Early Stopping: Training stops when validation accuracy fails to improve for multiple consecutive epochs
3. Results and Takeaways
The final model achieved the following on the 120-class classification task:
| Metric | Value |
|---|---|
| Test Set Accuracy | 91% |
| Average Loss | 0.009 |
| Kaggle Score | 0.30508 |
From nearly zero foundation in neural networks to ultimately building a three-model ensemble pipeline and achieving respectable results on Kaggle—the core takeaway of this project is the methodology of continuous iteration in the face of failure: each failure tells us what the model is still lacking, and each improvement is one step closer to the optimal solution. This debugging mindset applies not only to deep learning but is also a universal logic for engineering problem-solving.
Comments