From Point Cloud to Semantics: Deploying SpatialLM on the RDK X5 Edge Board
SpatialLM is a large AI model capable of "understanding" 3D space. This article documents how to deploy it onto a palm-sized embedded development board, achieving on-device spatial semantic understanding.
1. Why Squeeze a Large Model into an Edge Device?
In 2025, the ManyCore team published SpatialLM at NeurIPS — a large language model for 3D spatial understanding. Think of it as a "spatial version of ChatGPT": feed it a segment of point cloud data (3D scan results), and it tells you — where the walls are, where the doors are, where the bed is, which direction the sofa faces.
But SpatialLM natively depends on GPU execution. Robots, drones, AR glasses — these real-world devices have extremely limited computing power. If large models can only run in the cloud, they will never truly enter the physical world.
Thus, this project was born: deploy SpatialLM onto the D-Robotics RDK X5 (with only 10 TOPS of compute), enabling edge devices to "grow their own eyes."
2. System Architecture: PC Encoding + RDK X5 Inference
To balance precision and efficiency, we adopted a separated deployment architecture:
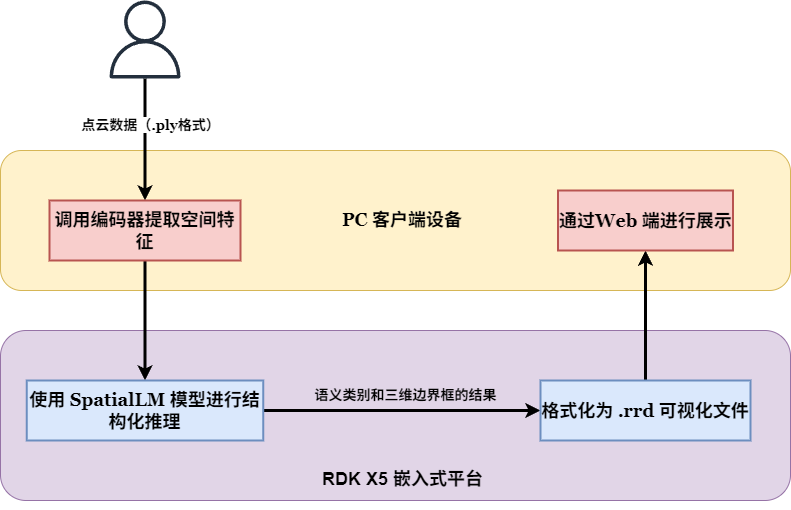
| Stage | Location | Task |
|---|---|---|
| Feature Encoding | PC (GPU) | Compress raw point cloud into feature vectors using the SONATA encoder |
| Semantic Inference | RDK X5 (CPU) | Load lightweight SpatialLM model, output semantic labels and 3D bounding boxes |
| Visualization | PC Web | Render interactive 3D scenes using the Rerun tool |
The entire workflow is automated: user uploads a .ply point cloud via the web interface → PC encodes → network transmission to RDK X5 → model inference → results sent back to PC and rendered.
3. Three Inference Modes, Flexible Adaptation to Different Scenarios
SpatialLM supports three structured inference tasks, covering spatial understanding needs from coarse to fine:
- Layout Estimation: identify the spatial positions of walls, doors, and windows
- Object Detection: detect furniture categories and 3D bounding boxes (supporting 59 furniture categories)
- Structured Reconstruction: combine both above for complete spatial modeling
The most compelling feature is Zero-shot generalization capability: specify target categories using natural language (e.g., "find all chairs and tables"), and the model can focus detection without retraining.

4. Results Showcase
Below are the actual runtime results from point cloud input to semantic annotation. The model successfully identified objects such as beds, nightstands, windows, doors, wall art, and wardrobes in a bedroom scene, intuitively presented with 3D bounding boxes and semantic labels.

From raw point cloud to a semantically labeled 3D scene, the entire pipeline requires zero manual annotation.
5. Technical Highlights
1. Compute Partitioning — Trading Architecture for Performance
Offload the computationally intensive 3D point cloud encoding to a PC GPU, keeping only lightweight LLM inference on the embedded side. Even 10 TOPS of compute can drive a large model.
2. Large Model Lightweighting
Adapted the originally CUDA-dependent SpatialLM to run purely on CPU, and is currently exploring BPU quantization acceleration — aiming to reduce inference time from minutes to seconds.
3. The Magic of LLM Generalization
Traditional 3D detection models require re-annotation and retraining for every new object category. SpatialLM natively supports zero-shot detection of arbitrary categories — this is the core breakthrough brought by the language model paradigm.
4. Engineering Closed Loop
From point cloud upload, encoding transmission, model inference, to visualization rendering — the entire chain is connected end-to-end, with open-source, reproducible code.
6. Application Outlook
Edge-side spatial understanding capability is key infrastructure for embodied intelligence to enter the real world:
- Service Robots: walk into an unfamiliar room and instantly understand the layout and object positions
- Autonomous Navigation: drones / autonomous vehicles performing real-time perception and obstacle avoidance in dynamic environments
- AR / VR: use a phone to record a short video and automatically generate a structured 3D model
When large models are no longer imprisoned in data centers but enter every embedded chip — that is when spatial intelligence truly begins to land.
7. Project Links
- Project Repository: SpatialLM_on_RDKX5
- Upstream Paper: SpatialLM (NeurIPS 2025) | Official Repository (4.5k⭐)
- Hardware Platform: D-Robotics RDK X5 (8×A55 @1.5GHz, 10 TOPS BPU, 8GB RAM)
Comments