When Robotic Arms Learn to See and Hear: An Intelligent Robotic Arm System Based on GLM-4V and SAM
📅 This project was completed in 2023 as an early exploration of combining multimodal large models with robotic control.
1. Background: Making Robotic Arms "Understand Human Speech"
In 2023, multimodal large models such as GPT-4V and GLM-4V were released successively. They could not only read text but also "see" images—this opened a brand new door for robotic control.
Traditional robotic arm programming requires defining joint trajectories frame by frame, which is time-consuming, labor-intensive, and has zero generalization capability. Multimodal large models, however, inherently possess semantic understanding + visual perception capabilities—what if a large model could directly "command" a robotic arm?
With this question in mind, we developed an intelligent robotic arm system based on the GLM-4V multimodal large model: users simply state the task in natural language (e.g., "pick up the block on the table"), and the system autonomously completes the full perception-to-execution closed loop.

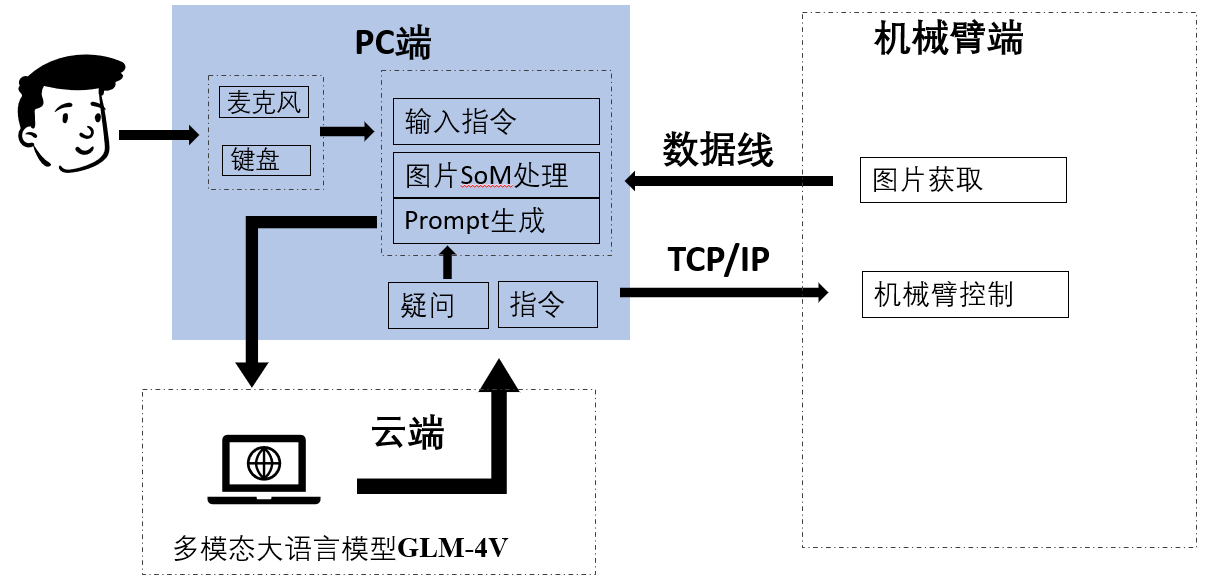
2. System Architecture: Four Modules Working in Unison
The system consists of four core modules, with data flowing between them to form a complete perception-decision-execution pipeline:
\n
| Module | Technical Solution | Deployment Location | Responsibility |
|---|---|---|---|
| Speech Recognition | OpenAI Whisper | PC Local | Transcribes user spoken commands into text |
| Visual Perception | SAM + SoM Calibration | PC Local | Image segmentation, object localization, coordinate generation |
| Semantic Decision-Making | GLM-4V (API) | Cloud | Task decomposition, action planning, API selection |
| Action Execution | myCobot 280 Six-Axis | Desktop | Receives high-level commands, executes physical grasping |
\n
The processing flow for a typical command ("clean the desk"): speech is transcribed by Whisper → camera captures an image and SAM performs visual calibration → the annotated image and text prompt are sent together to GLM-4V → the large model decomposes the task into sub-steps and outputs a sequence of robotic arm API calls → the robotic arm executes them one by one.
3. Core Innovation: SoM Visual Calibration
Although multimodal large models can "see" images, the object position information they output is often only vague textual descriptions (e.g., "on the upper left of the desk"), which cannot be directly converted into precise coordinates usable by a robotic arm. This was the core pain point for deploying large models in robotic control at the time.
We introduced the SoM (Set-of-Mark) visual calibration method to solve this problem:
- SAM Segmentation: Using Meta's Segment Anything Model (SAM) on the camera-captured desk image, generate precise masks for each object;
- Coordinate Calculation: Average all pixel coordinates within each mask to obtain the object's center position;
- Numerical Marking: Overlay numerical labels (e.g., 0, 1, 2) on each object in the image;
- Large Model Recognition: Send the annotated image to GLM-4V, allowing the model to precisely say "grasp object 1" rather than vaguely describe a location.


This approach deeply integrates GLM-4V's semantic understanding capability with SAM's high-precision segmentation capability—the large model no longer needs to output physical coordinates but simply references labeled object numbers, while SAM handles precise positioning. Each does what it does best.
4. Core Innovation: Multi-Agent Prompt Engineering
Making a large model directly output robotic arm control commands sounds simple, but the practical challenges are numerous: tasks need decomposition, execution needs supervision, and failures need reflection. A single prompt cannot adequately handle all these roles.
We designed a three-agent prompt workflow, distributing different responsibilities across three "bots":
\n
| Agent | Role | Responsibility |
|---|---|---|
| TaskBot | Task Planner | Receives user commands + images, decomposes complex tasks into sub-task sequences, selects appropriate robotic arm APIs for each sub-task |
| JudgeBot | Quality Reviewer | Determines whether each sub-task requires re-photographing for confirmation (tasks involving object movement need it; pure computation tasks do not) |
| LastBot | Reflection Corrector | Reviews results after task execution, detects failures, and generates correction strategies—e.g., re-localizing an object after it has been accidentally pushed |
\n
The collaboration of the three forms a decision-making closed loop with built-in error correction capability. Moreover, we designed two workflow modes: High-Precision Mode (all three Bots active, suitable for complex tasks) and Fast Mode (skipping LastBot, suitable for simple commands), allowing flexible switching between accuracy and response speed.
5. Engineering Implementation: Pitfalls and Solutions
Between a working demo and stable operation lies a mass of engineering details. Here are several real-world problems encountered and their solutions:
- 🛠️ Pain Point 1: Inaccurate coordinate output from the large model
GLM-4V directly outputs object positions as vague natural language descriptions, unusable by the robotic arm.
→ Introduced SAM + SoM calibration; the large model only needs to reference label numbers, with precise coordinates calculated by SAM. - 🛠️ Pain Point 2: Robotic arm fails to reach the specified position
Due to mechanical errors and sensor precision limitations, a single movement command may not bring the robotic arm to the target coordinates.
→ Implemented repeated movement and checking mechanism: after each movement, call_get_coords_with_retry()to verify actual coordinates; if the error exceeds 10%, automatically retry. - 🛠️ Pain Point 3: Image coordinate system misaligned with robotic arm coordinate system
SAM outputs image pixel coordinates, but the robotic arm requires physical spatial coordinates.
→ Ruler calibration method: place a ruler under the camera, calibrate two points on the image, calculate the pixel-to-physical-size ratio, and establish the mapping between the two coordinate systems. - 🛠️ Pain Point 4: Overly rich prompts cause the model to "selectively execute"
When constraint instructions are too numerous, large models do not necessarily follow every single one strictly.
→ Designed supervision and self-review mechanism: decompose key constraints into independent check steps and verify them one by one through JudgeBot. - 🛠️ Pain Point 5: Robotic arm motion delay causes command loss
The code sends the next command immediately after issuing a motion command, before the robotic arm has time to respond.
→ Added appropriatetime.sleep()delays after each motion command to ensure the robotic arm has enough time to complete the current action.
It is worth noting that the project also encapsulated a set of high-level robotic arm command APIs—no longer having the large model output low-level joint angles, but encapsulating them into semantic-level APIs (grab("block"), move_to("paper ball"), etc.), significantly reducing the model's output error rate.
6. Results and Significance
After the above optimizations, the system achieved a "say one sentence, the robotic arm does it all" zero-shot operation closed loop:
- ✅ Zero-Shot Generalization: No training required for specific objects; any desktop object can be identified and grasped
- ✅ Multimodal Fusion: GLM-4V (semantics) + SAM (localization) + Whisper (speech) three models working in synergy
- ✅ Efficiency Leap: Single task time reduced by approximately 80%, far exceeding the traditional frame-by-frame programming approach
- ✅ Robust and Reliable: Self-developed retry mechanisms and infinite-loop detection ensure system stability in real-world environments
The core insight of this project—large models need not replace traditional vision algorithms but should instead complement them, each doing its own job—letting the LLM handle the high-level reasoning and planning it excels at, while letting SAM handle the precise perception it excels at. The philosophy of "fusion rather than replacement" later carried through all my subsequent work in embodied intelligence.
Further Reading
- GLM-4V Multimodal Large Model: Zhipu AI Open Platform
- SAM (Segment Anything Model): Meta AI Research
- myCobot Six-Axis Collaborative Robot: Elephant Robotics
- OpenAI Whisper: openai/whisper
- SoM (Set-of-Mark) Paper: Set-of-Mark Visual Prompting for VLMs
Comments