Embodied AI Collaborative Deployment: A Cloud-Edge-End Multi-Robot Agent Framework
As embodied intelligence surges, using large models to command robot operations has become a trend. However, in low-cost automation scenarios such as miniature logistics sandboxes, real-world deployment faces enormous challenges. This project uses two PuppyPi quadruped robot dogs and one Vansbot six-axis robot arm as control targets, aiming to solve the following three major pain points:
OpenClaw Two Dog One-Arm Demo Video, Mission: Dog1 goes to charging area to charge, while Dog2 goes to loading area to load yellow blocks and then travels to unloading area to unload.
- Terminal computing and perception deficiencies: low-cost robot dogs have extremely weak onboard computing power — no LiDAR, no forward-facing camera, not even reliable odometry (essentially running "blind"). They cannot independently run any complex localization or planning algorithms.
- Heterogeneous device communication fragmentation: the robot arm uses HTTP, the robot dogs communicate via WebSocket and low-level serial interfaces, while ROS operates on its own paradigm. Traditional tightly coupled coding leads to extremely poor system scalability (adding one device requires refactoring massive amounts of code).
- Multi-robot deadlock risks: multiple robots share the same physical space. Sequential waiting causes severe time penalties, and if any device becomes stuck due to network issues or physical slippage, it can easily drag down the entire pipeline.
To enable this group of computationally constrained, communication-incompatible "dumb terminals" to understand natural language instructions and collaborate smoothly, I designed and implemented a cloud-edge-end three-layer decoupled Agent architecture.
Core Architecture: A Decoupled Design Where Cloud, Edge, and End Each Play Their Role
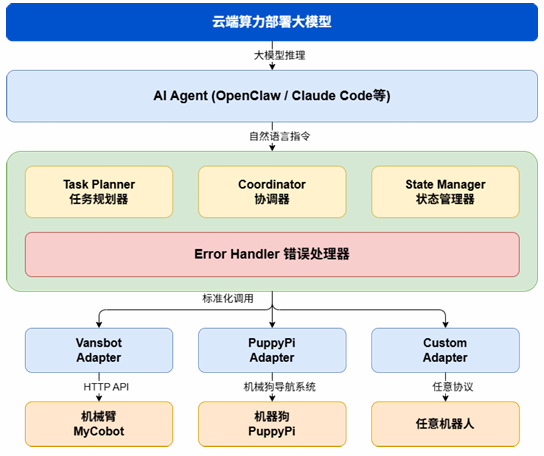
Cloud — Decision Layer: directly interfaces with large language models. The LLM does not need to concern itself with low-level hardware protocols; it only needs to parse natural language (e.g., "hand the block on the left to Dog No. 2") into a structured Directed Acyclic Graph (DAG) task sequence.
Edge — Global Perception & Scheduling Hub: the core of this project. The main control PC is equipped with an Intel RealSense D455 depth camera providing a "god's-eye view." It serves two major functions: first, providing real-time high-precision pose estimation for all robots through global vision; second, using the OpenClaw Agent framework's adapter pattern to smooth over underlying communication differences (HTTP, serial, etc.) and uniformly dispatch action commands downward.
End — Physical Execution Layer: the PuppyPi quadruped robot dogs and the Vansbot robot arm do not run any complex logic. They only receive structured commands — servo angles, forward velocity — and execute inverse kinematics. All computational burden is offloaded to the edge layer, keeping the terminal layer extremely lightweight and replaceable.
Conquering Two Major Challenges: Visual Mapping and Physical Control
Challenge 1: The Quadruped "Blind Dog's" Sideslip Drift
The PuppyPi has weak self-perception capabilities — no odometry, no LiDAR, with positioning entirely relying on the overhead D455. Even more fatal is the slippage characteristic of the quadruped linkage structure: significant lateral drift occurs during turning, and traditional PID navigation tends to "overshoot," repeatedly calibrating in place after reaching the target — both time-consuming and prone to deviating from the handover position.
The solution is a lookahead-based Pure Pursuit algorithm. The robot dog does not charge directly at the target; instead, it first reaches a buffer point approximately 28 cm behind the target, then approaches along a smooth arc. The algorithm continuously computes the tracking curvature κ = 2Δy/Ld² based on the lateral position error for continuous kinematic correction. Combined with a 13 cm height-compensated ray projection to eliminate coordinate shrinkage caused by overhead perspective, the entire localization pipeline is: YOLOv8-Pose detection of head/tail keypoints → 5×5 neighborhood median depth extraction → ray intersection projection → pose synthesis → Pure Pursuit navigation. This combination enables "blind dog" centimeter-level precision docking.
Challenge 2: Multi-Robot Deadlock and Checkpoint-Resume
When multiple robots share the same physical space, a single stuck robot can bring down the entire system. This project embeds a periodic status polling and monitoring mechanism inside the OpenClaw hub: an independent monitoring thread queries each robot's status (connection, busy, position, etc.) every second, updating a local cache. Drawing from operating system deadlock prevention theory, the focus is on breaking the "hold and wait" condition — when a robot is detected holding a communication lock for an extended period without releasing it, the monitoring thread forcibly preempts and issues a reset command, interrupting the deadlock cycle.
In weak-network or partial packet-loss scenarios, the status polling mechanism also enables automatic checkpoint-resume: when the main program detects a terminal unresponsive for an extended period, it catches the exception, triggers the hub to re-count and reissue commands, achieving fault recovery without manual intervention.
Project Results and Quantitative Metric Validation
Three quantitative tests were conducted on a standardized indoor tabletop platform:
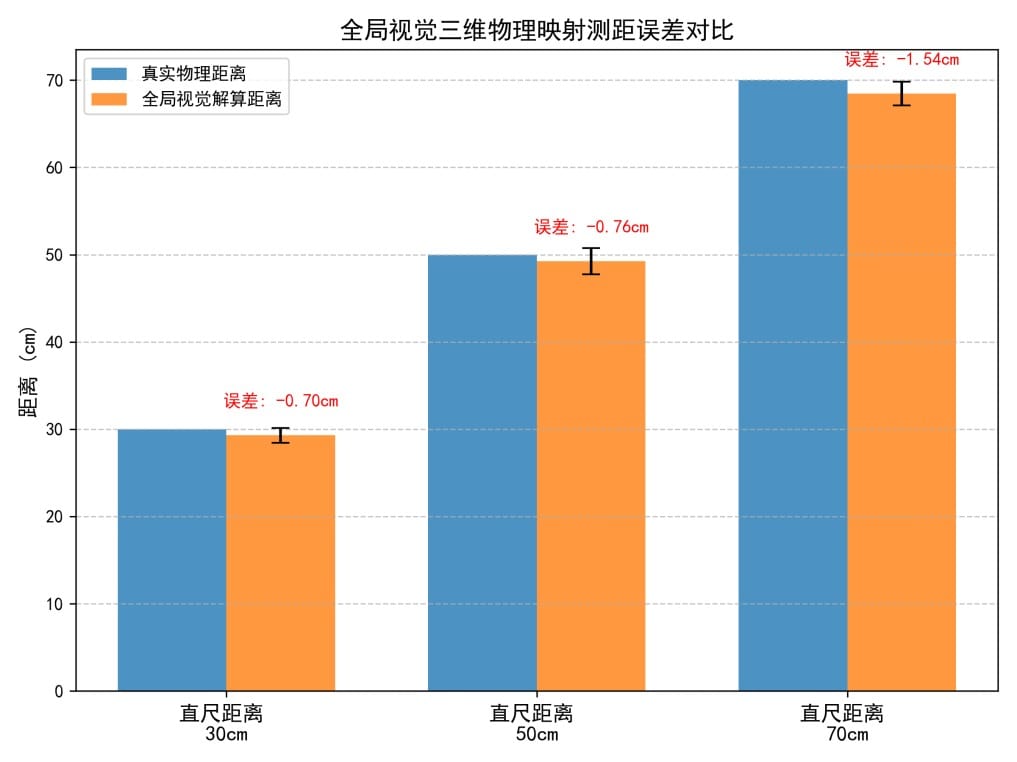
Global Visual Ranging Accuracy: using a physical ruler at three spans (30 cm, 50 cm, 70 cm), each with 20 groups (60 groups total). The identified mean at 30 cm standard distance was approximately 29.30 cm, with an overall standard deviation of 0.86 cm. Within the core region, pose accuracy errors with height projection mapping rarely exceeded 1 cm.
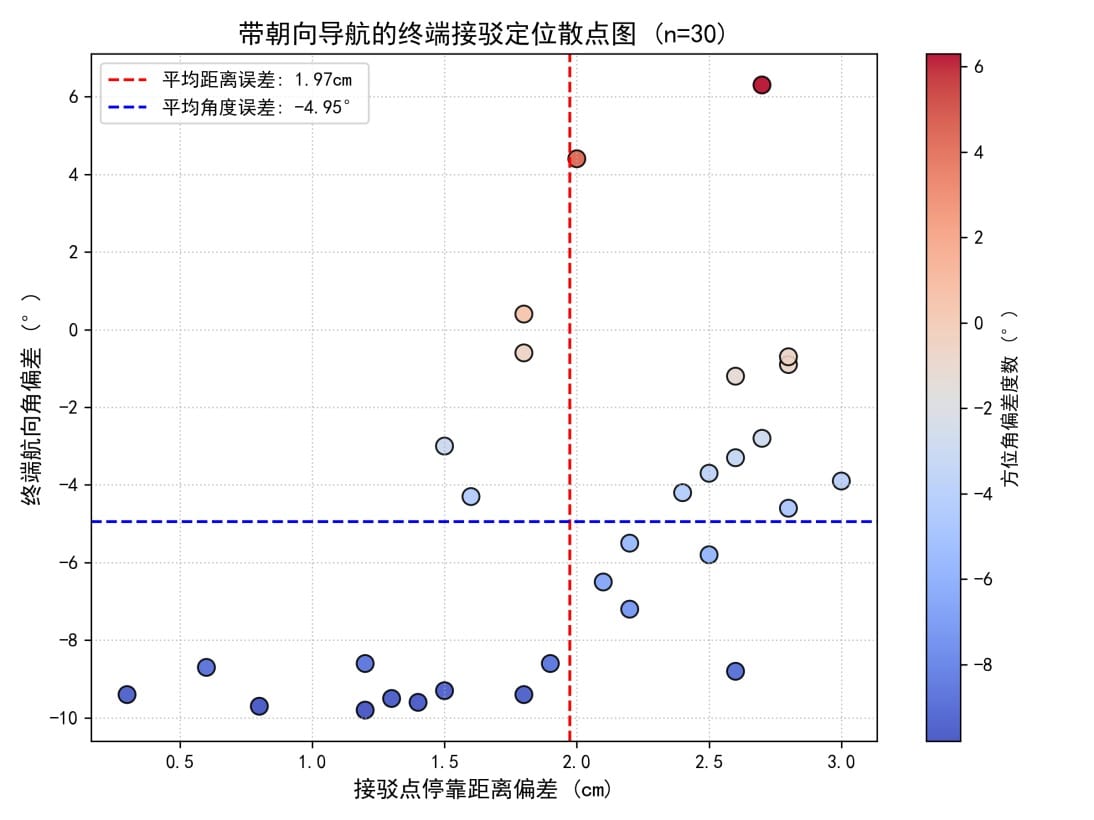
Robot Dog Docking Precision: from 30 different starting positions and orientations, using Pure Pursuit navigation to enter a fixed handover point. Docking endpoints were densely controlled within a 3 cm deviation circle, and terminal yaw angle range was locked within 9° (median distribution error 4°-6°).
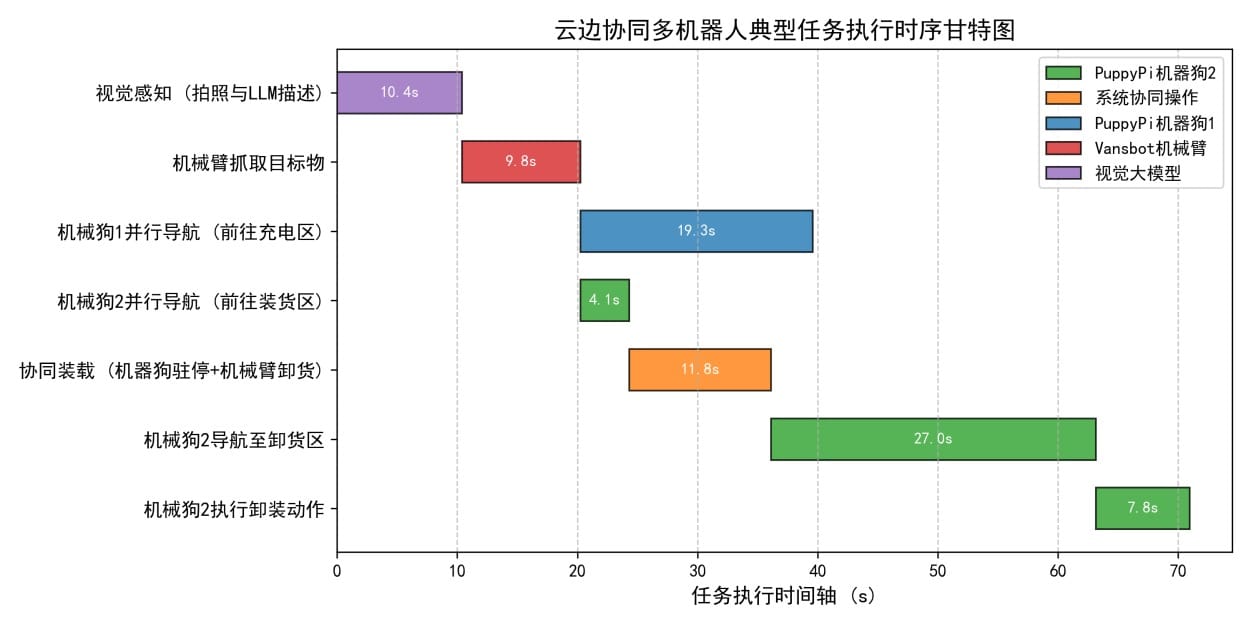
End-to-End Parallel Efficiency and Robustness: in a typical "two dogs, one arm collaborative transport" task, DAG parallel scheduling collapses the movement action times of the two robot dogs, with overall completion time of 68-104 seconds. In end-to-end testing of 10 complex concurrent tasks, the first-run direct success rate was approximately 90%, but the system could automatically diagnose anomaly types, execute state resets, and reissue commands after failure, achieving a final success rate of 100%.
Technology Stack Overview
- ☁️ Cloud: LLM natural language parsing → DAG task tree generation
- 💡 Edge: Python + OpenClaw Framework | YOLOv8-Pose | RANSAC tabletop calibration | Ray intersection projection | Pure Pursuit | Adapter pattern multi-protocol communication
- 🤖 End: PuppyPi quadruped robot dog + Vansbot six-axis robot arm
- 📷 Perception: Intel RealSense D455 (1280×720 RGB-D)
The core value of this framework lies in bridging the semantic understanding capability of large models with the physical execution of low-compute hardware — enabling a group of "blind and mute" robots to collaborate under a unified Agent hub. More importantly, it is not a paper design, but a complete engineering system that runs end-to-end on real hardware and withstands quantitative validation.
The Vansbot six-axis robot arm in this project inherits the visual perception and natural language control capabilities from the earlier GLM-4V Intelligent Robot Arm Project, and on this foundation, it was integrated into the multi-robot system through OpenClaw unified scheduling. Code is open source: Multi-Robot Collaboration Framework | Robot Dog Autonomous Navigation System.
Comments